怎么用vs做网站开发郑州网站优化
Kafka-Eagle 监控
Kafka-Eagle 框架可以监控 Kafka 集群的整体运行情况,在生产环境中经常使用。
MySQL环境准备
Kafka-Eagle 的安装依赖于 MySQL,MySQL 主要用来存储可视化展示的数据。
安装步骤参考:P61 尚硅谷 kafka监控_MySQL环境准备
Kafka 环境准备
-
关闭 Kafka 集群
[atguigu@hadoop102 kafka]$ kf.sh stop -
修改
/opt/module/kafka/bin/kafka-server-start.sh[atguigu@hadoop102 kafka]$ vim bin/kafka-server-start.sh修改如下参数值:
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; thenexport KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" fi为
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; thenexport KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"export JMX_PORT="9999"#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" fi初始内存只分配1G,如果要使用 Eagle 功能,我们可以将内存设置为 2G。
注意:修改之后在启动 Kafka 之前要分发至其他节点。
[atguigu@hadoop102 bin]$ xsync kafka-server-start.sh
Kafka-Eagle 安装
-
官网:https://www.kafka-eagle.org/
-
上传压缩包
kafka-eagle-bin-2.0.8.tar.gz到集群/opt/software目录 -
解压到本地
[atguigu@hadoop102 software]$ tar -zxvf kafka-eagle-bin-2.0.8.tar.gz -
进入刚才解压的目录
[atguigu@hadoop102 kafka-eagle-bin-2.0.8]$ ll总用量 79164 -rw-rw-r--. 1 atguigu atguigu 81062577 10 月 13 00:00 efak-web-2.0.8-bin.tar.gz -
将
efak-web-2.0.8-bin.tar.gz解压至/opt/module[atguigu@hadoop102 kafka-eagle-bin-2.0.8]$ tar -zxvf efak-web-2.0.8-bin.tar.gz -C /opt/module/ -
修改名称
[atguigu@hadoop102 module]$ mv efak-web-2.0.8/ efak -
修改配置文件
/opt/module/efak/conf/system-config.properties[atguigu@hadoop102 conf]$ vim system-config.properties###################################### # multi zookeeper & kafka cluster list # Settings prefixed with 'kafka.eagle.' will be deprecated, use 'efak.'instead ###################################### efak.zk.cluster.alias=cluster1 cluster1.zk.list=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka ###################################### # zookeeper enable acl ###################################### cluster1.zk.acl.enable=false cluster1.zk.acl.schema=digest cluster1.zk.acl.username=test cluster1.zk.acl.password=test123 ###################################### # broker size online list ###################################### cluster1.efak.broker.size=20 ###################################### # zk client thread limit ###################################### kafka.zk.limit.size=32 ###################################### # EFAK webui port ###################################### efak.webui.port=8048 ###################################### # kafka jmx acl and ssl authenticate ###################################### cluster1.efak.jmx.acl=false cluster1.efak.jmx.user=keadmin cluster1.efak.jmx.password=keadmin123 cluster1.efak.jmx.ssl=false cluster1.efak.jmx.truststore.location=/data/ssl/certificates/kafka.truststore cluster1.efak.jmx.truststore.password=ke123456 ###################################### # kafka offset storage ###################################### # offset 保存在 kafka cluster1.efak.offset.storage=kafka ###################################### # kafka jmx uri ###################################### cluster1.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi ###################################### # kafka metrics, 15 days by default ###################################### efak.metrics.charts=true efak.metrics.retain=15 ###################################### # kafka sql topic records max ###################################### efak.sql.topic.records.max=5000 efak.sql.topic.preview.records.max=10 ###################################### # delete kafka topic token ###################################### efak.topic.token=keadmin ###################################### # kafka sasl authenticate ###################################### cluster1.efak.sasl.enable=false cluster1.efak.sasl.protocol=SASL_PLAINTEXT cluster1.efak.sasl.mechanism=SCRAM-SHA-256 cluster1.efak.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramL oginModule required username="kafka" password="kafka-eagle"; cluster1.efak.sasl.client.id= cluster1.efak.blacklist.topics= cluster1.efak.sasl.cgroup.enable=false cluster1.efak.sasl.cgroup.topics= cluster2.efak.sasl.enable=false cluster2.efak.sasl.protocol=SASL_PLAINTEXT cluster2.efak.sasl.mechanism=PLAIN cluster2.efak.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainL oginModule required username="kafka" password="kafka-eagle"; cluster2.efak.sasl.client.id= cluster2.efak.blacklist.topics= cluster2.efak.sasl.cgroup.enable=false cluster2.efak.sasl.cgroup.topics= ###################################### # kafka ssl authenticate ###################################### cluster3.efak.ssl.enable=false cluster3.efak.ssl.protocol=SSL cluster3.efak.ssl.truststore.location= cluster3.efak.ssl.truststore.password= cluster3.efak.ssl.keystore.location= cluster3.efak.ssl.keystore.password= cluster3.efak.ssl.key.password= cluster3.efak.ssl.endpoint.identification.algorithm=https cluster3.efak.blacklist.topics= cluster3.efak.ssl.cgroup.enable=false cluster3.efak.ssl.cgroup.topics= ###################################### # kafka sqlite jdbc driver address ###################################### # 配置 mysql 连接 efak.driver=com.mysql.jdbc.Driver efak.url=jdbc:mysql://hadoop102:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull efak.username=root efak.password=000000 ###################################### # kafka mysql jdbc driver address ###################################### #efak.driver=com.mysql.cj.jdbc.Driver #efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull #efak.username=root #efak.password=123456 -
添加环境变量
[atguigu@hadoop102 conf]$ sudo vim /etc/profile.d/my_env.sh# kafkaEFAK export KE_HOME=/opt/module/efak export PATH=$PATH:$KE_HOME/bin注意:source /etc/profile
[atguigu@hadoop102 conf]$ source /etc/profile -
启动
-
注意:启动之前需要先启动 zk 以及 kafka
[atguigu@hadoop102 kafka]$ kf.sh start -
启动 efak
[atguigu@hadoop102 efak]$ bin/ke.sh startVersion 2.0.8 -- Copyright 2016-2021 ***************************************************************** * EFAK Service has started success. * Welcome, Now you can visit 'http://192.168.10.102:8048' * Account:admin ,Password:123456 ***************************************************************** * <Usage> ke.sh [start|status|stop|restart|stats] </Usage> * <Usage> https://www.kafka-eagle.org/ </Usage> ***************************************************************** -
如果停止 efak,执行命令:
[atguigu@hadoop102 efak]$ bin/ke.sh stop
-
Kafka-Eagle 页面操作
- 登录页面查看监控数据
- http://192.168.10.102:8048/
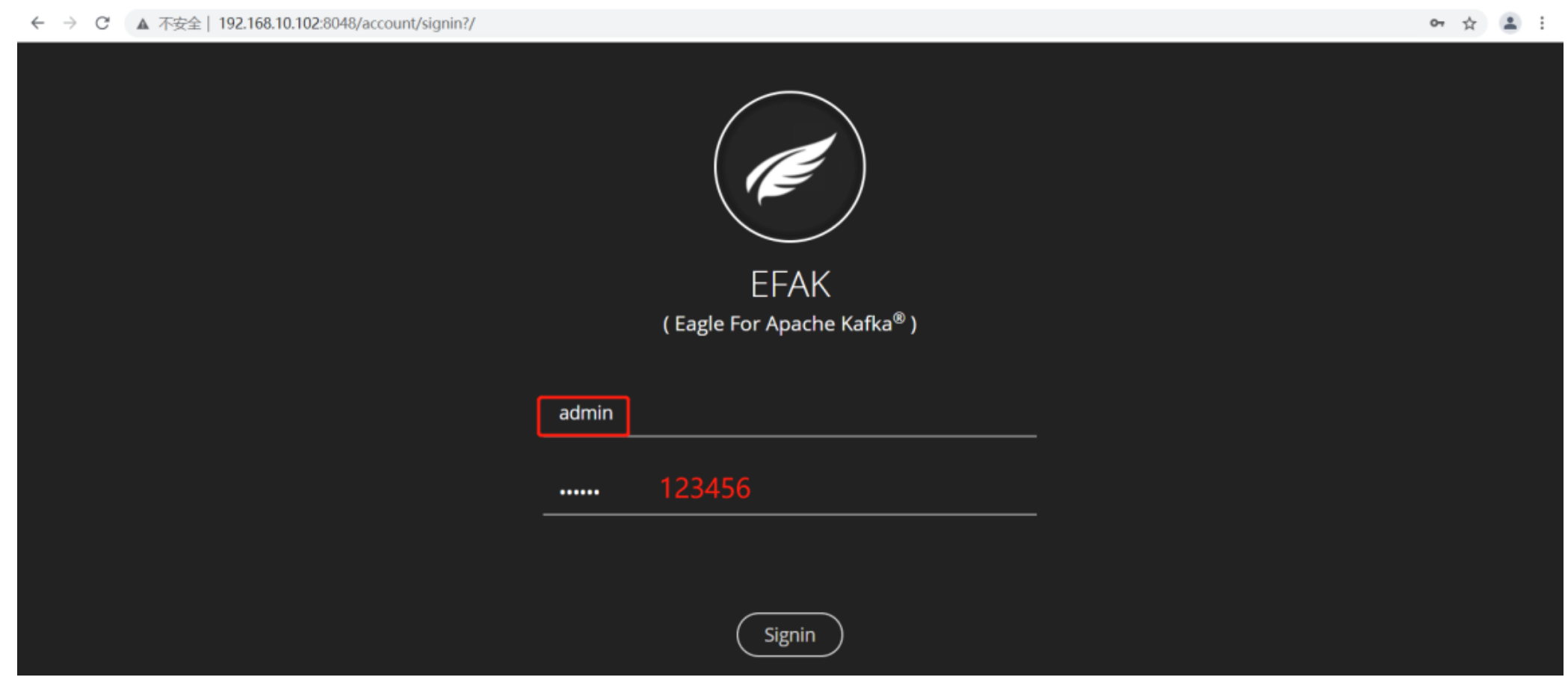
主面板
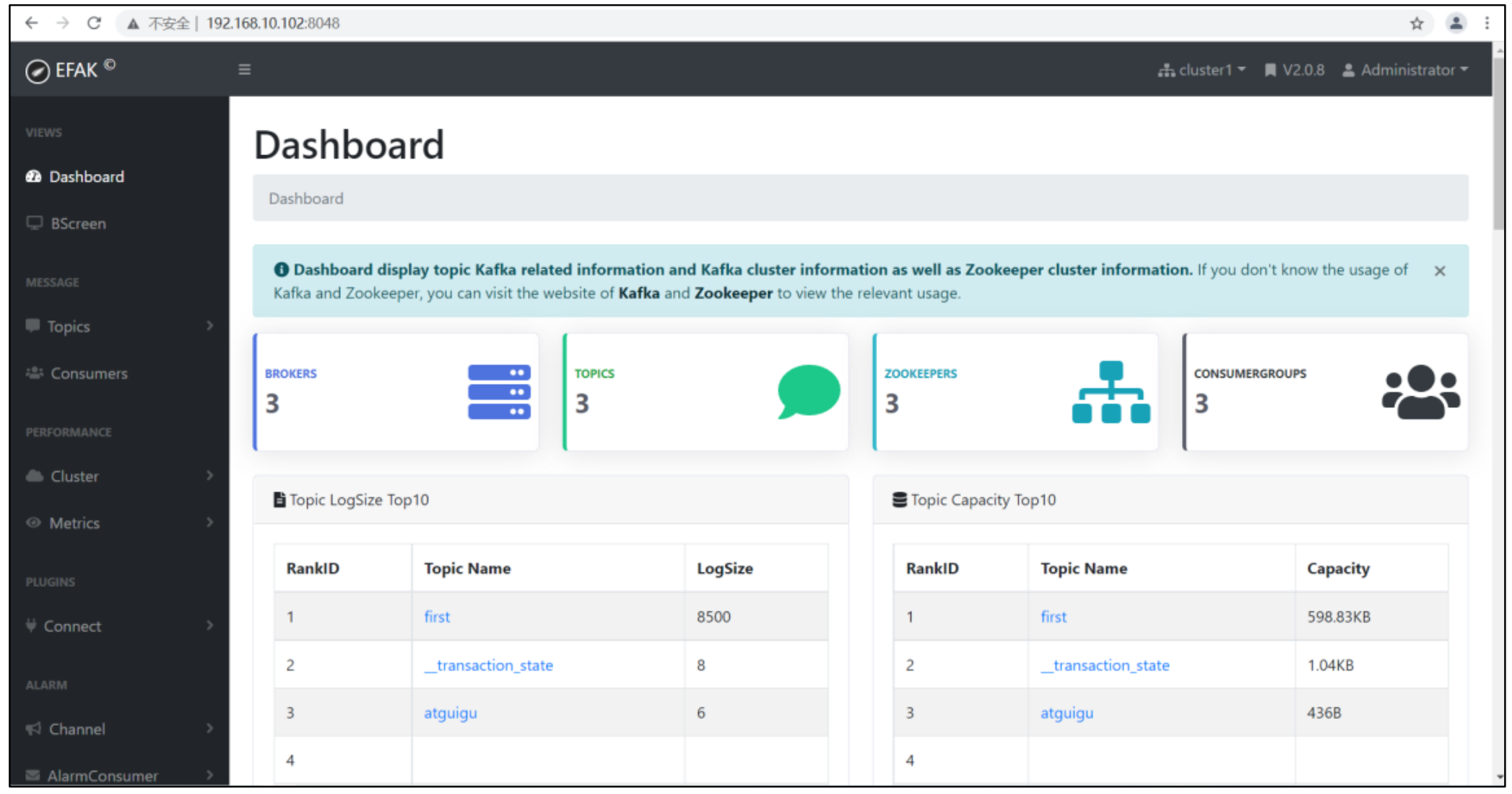
Brokers
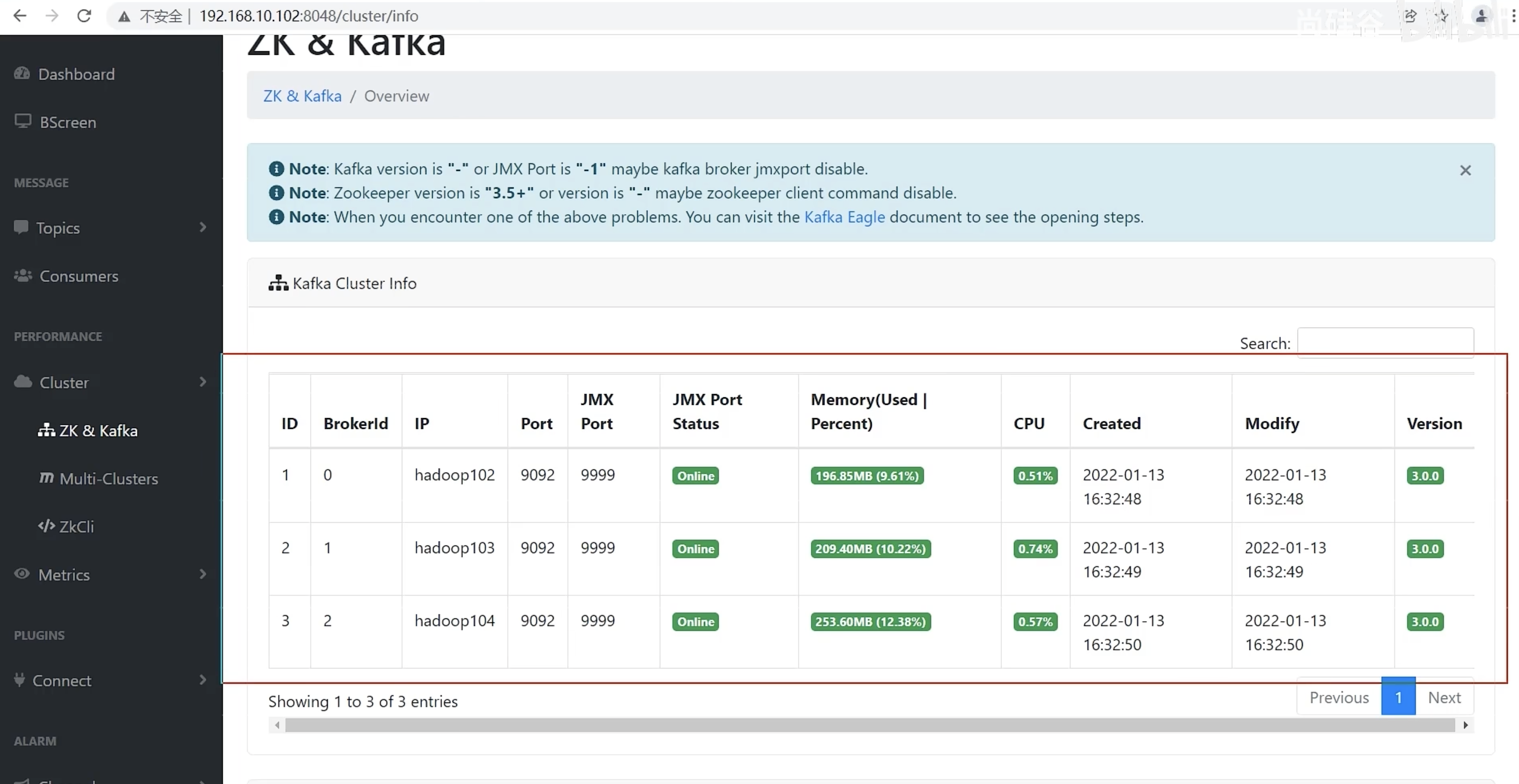
Topics
Zookeepers
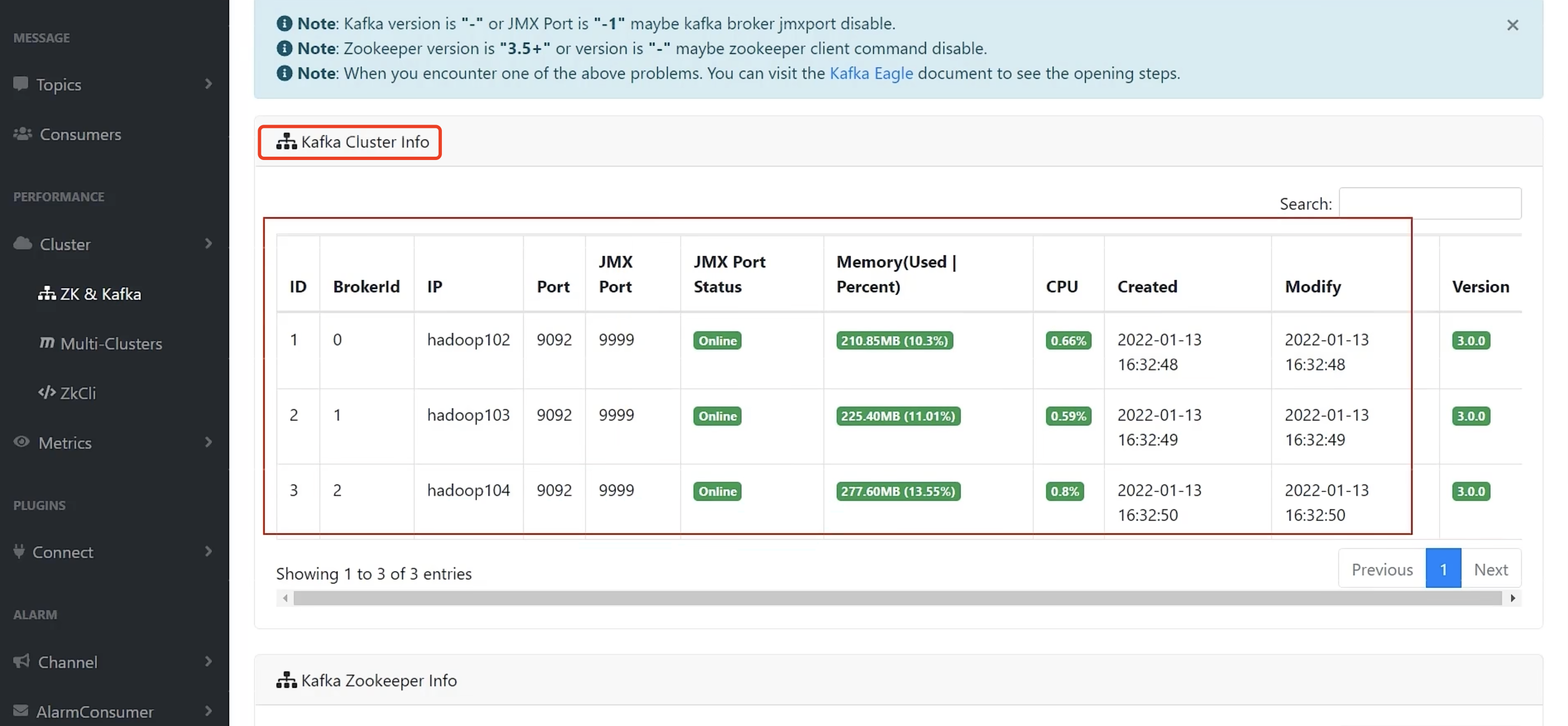
Consumers
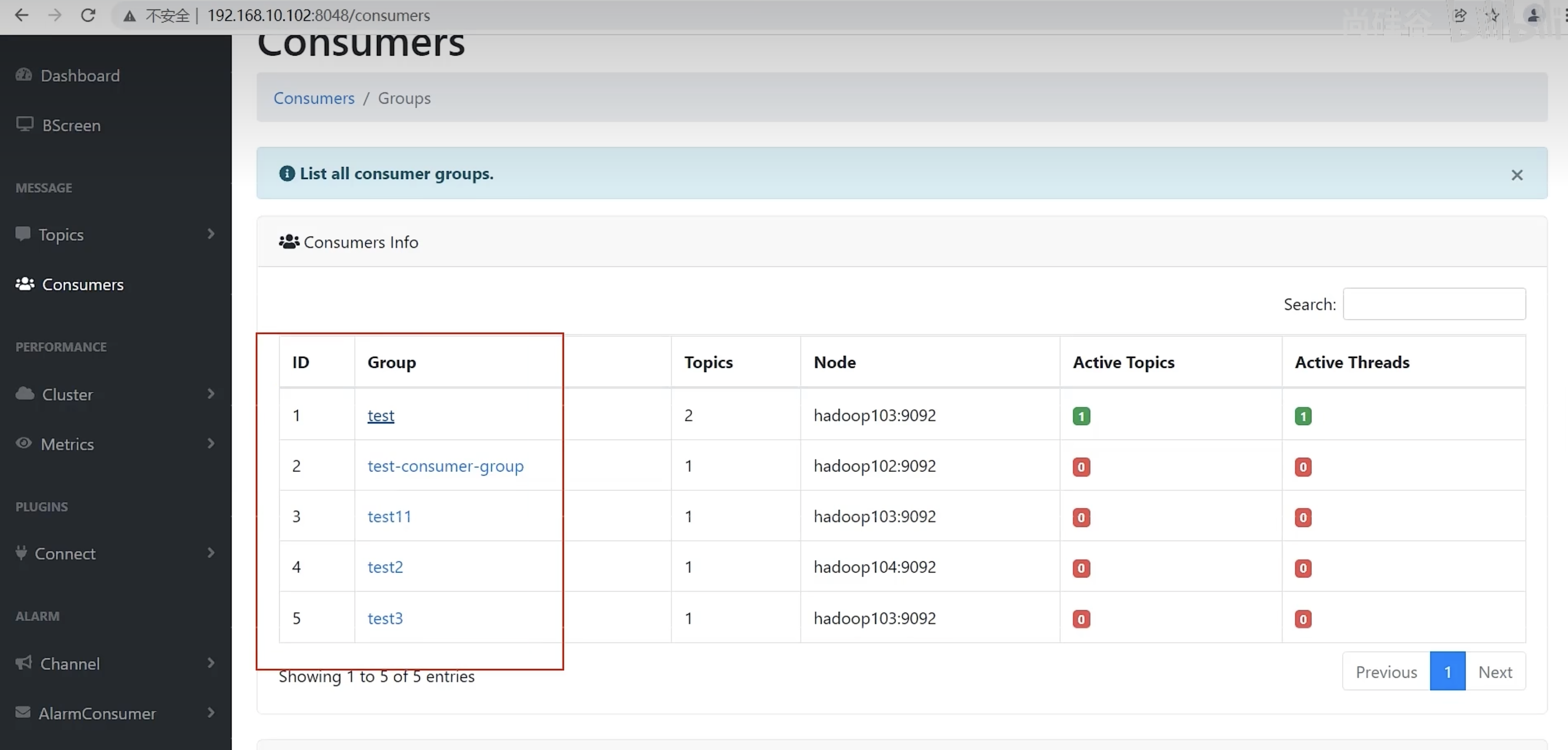
大屏信息
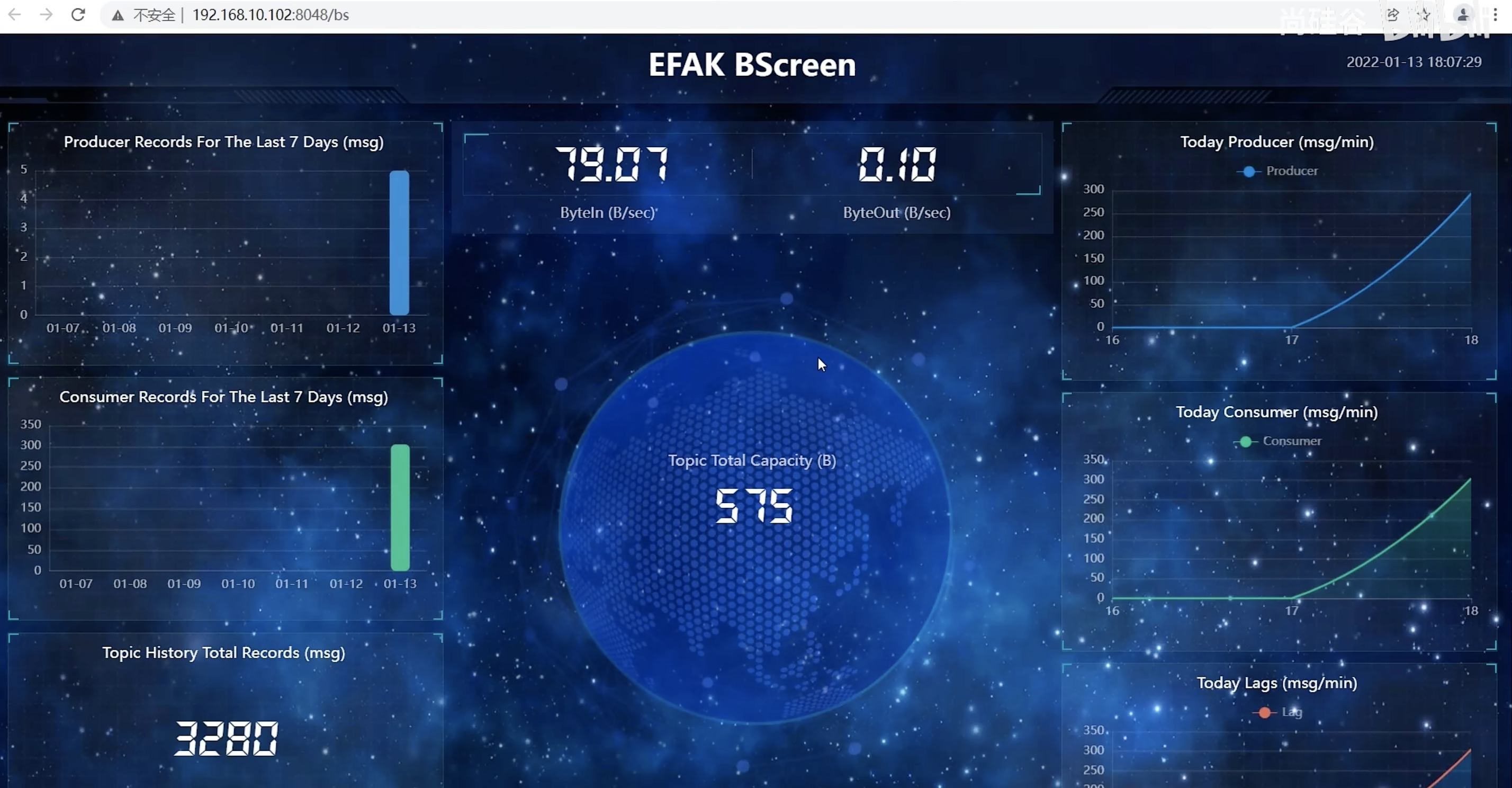
Kafka-Kraft 模式
Kafka-Kraft 架构
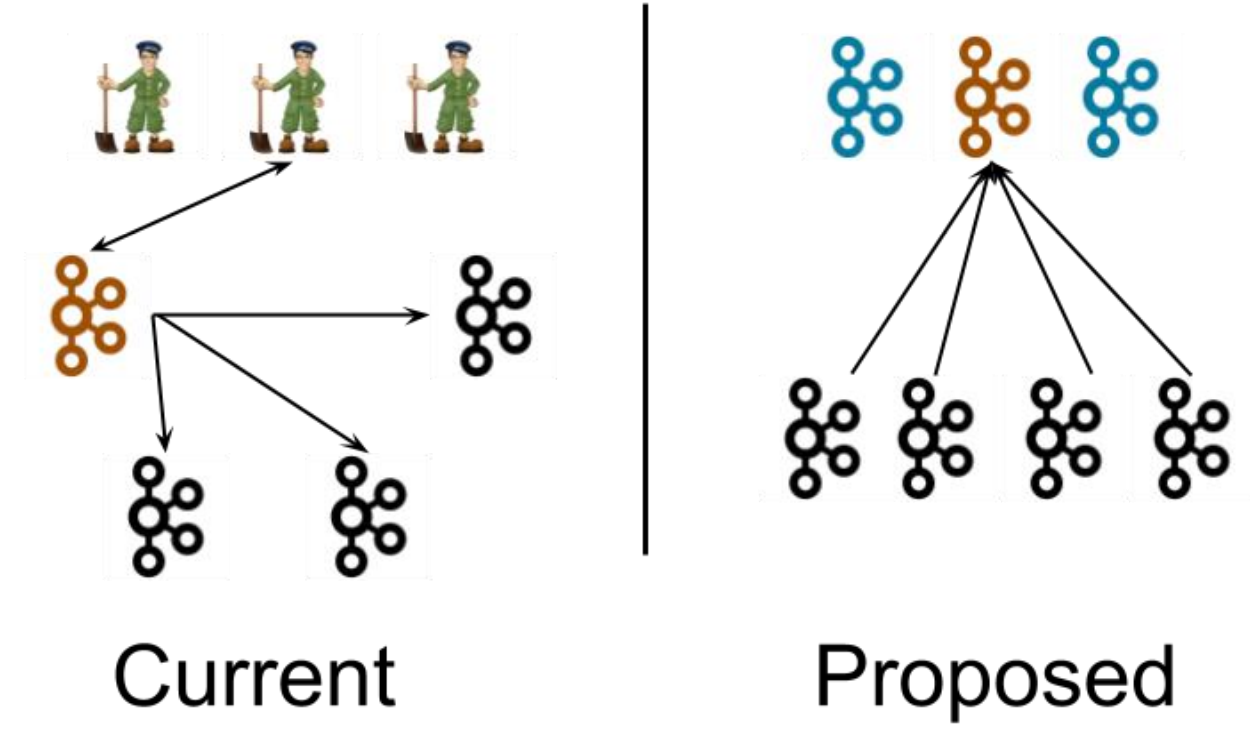
左图为 Kafka 现有架构,元数据在 zookeeper 中,运行时动态选举 controller,由 controller 进行 Kafka 集群管理。
右图为 kraft 模式架构(实验性),不再依赖 zookeeper 集群,而是用三台 controller 节点代替 zookeeper,元数据保存在 controller 中,由 controller 直接进行 Kafka 集群管理。
这样做的好处有以下几个:
- Kafka 不再依赖外部框架,而是能够独立运行;
- controller 管理集群时,不再需要从 zookeeper 中先读取数据,集群性能上升;
- 由于不依赖 zookeeper,集群扩展时不再受到 zookeeper 读写能力限制;
- controller 不再动态选举,而是由配置文件规定。
- 这样我们可以有针对性的加强 controller 节点的配置,而不是像以前一样对随机 controller 节点的高负载束手无策。
Kafka-Kraft 集群部署

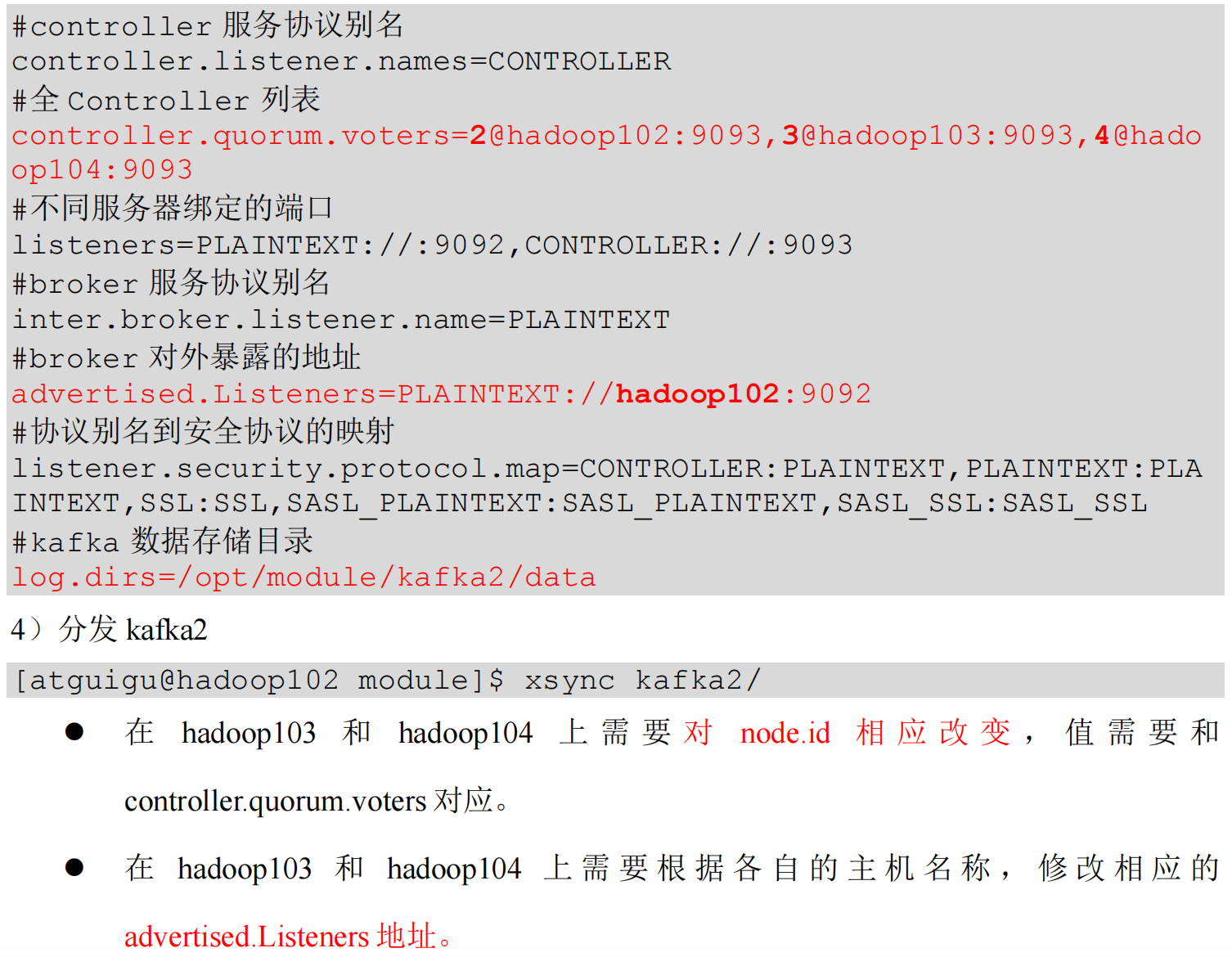


Kafka-Kraft 集群启动停止脚本
-
在
/home/atguigu/bin目录下创建文件kf2.sh脚本文件[atguigu@hadoop102 bin]$ vim kf2.sh脚本如下:
#! /bin/bashcase $1 in "start"){for i in hadoop102 hadoop103 hadoop104doecho " --------启动 $i Kafka2-------"ssh $i "/opt/module/kafka2/bin/kafka-server-start.sh -daemon /opt/module/kafka2/config/kraft/server.properties"done };; "stop"){for i in hadoop102 hadoop103 hadoop104doecho " --------停止 $i Kafka2-------"ssh $i "/opt/module/kafka2/bin/kafka-server-stop.sh "done };; esac -
添加执行权限
[atguigu@hadoop102 bin]$ chmod +x kf2.sh -
启动集群命令
[atguigu@hadoop102 ~]$ kf2.sh start -
停止集群命令
[atguigu@hadoop102 ~]$ kf2.sh stop
Kafka 集成
Kafka 集成 Flume
Flume 是一个在大数据开发中非常常用的组件,可以用于 Kafka 的生产者,也可以用于 Kafka 的消费者。
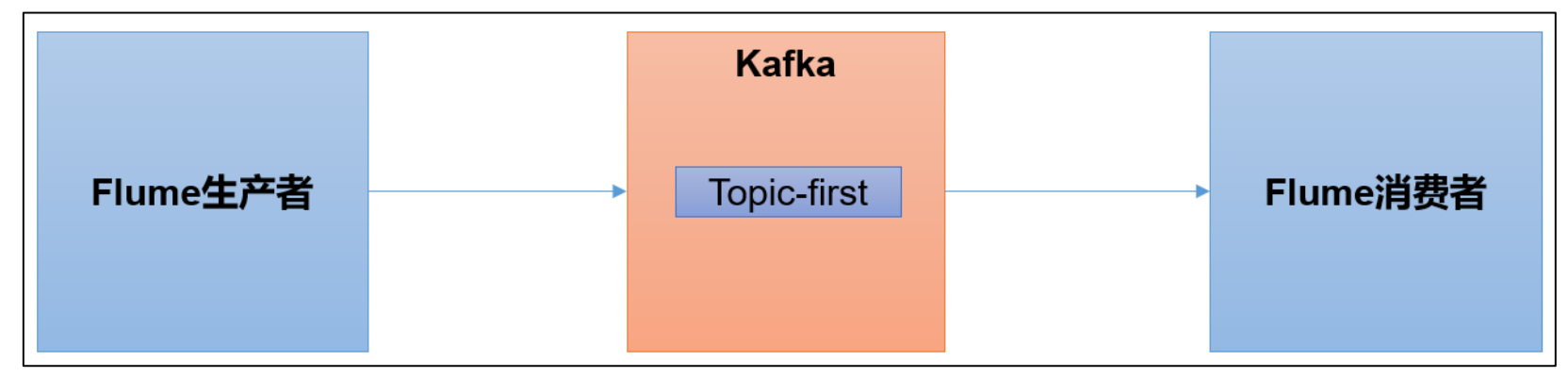
Flume 环境准备
-
启动 kafka 集群
[atguigu@hadoop102 ~]$ zk.sh start [atguigu@hadoop102 ~]$ kf.sh start -
启动 kafka 消费者
[atguigu@hadoop103 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first -
Flume 安装步骤
- 参考:P66 尚硅谷 Kafka 集成 Flume 环境准备
Flume 生产者
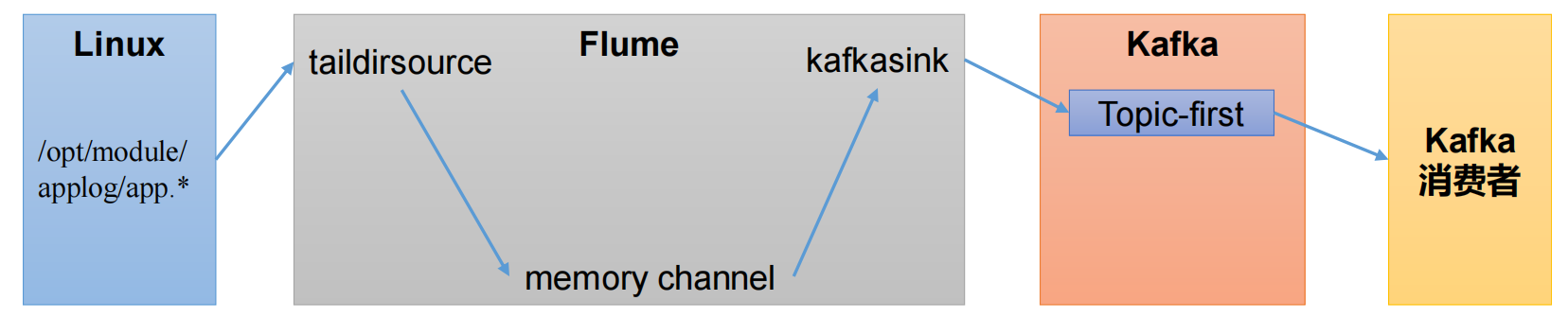
- 通过 Flume 实时监控
app.log文件数据的变化 - 使用 taildir source,支持断点续传、实时监控文件变化,并获取到数据
- 由于我们传输的就是普通的日志,没有必要追求太高的可靠性,使用 memory channel,完全基于内存,速度非常快;断电后会丢数据,最多丢 100 条日志(因为内存大小最大上线就是 100)
- 数据是发往到 kafka 的,所以使用 kafka sink
- 发到 first 主题中,启动消费者消费。
-
配置 Flume
-
在 hadoop102 节点的 Flume 的 job 目录下创建
file_to_kafka.conf[atguigu@hadoop102 flume]$ mkdir jobs [atguigu@hadoop102 flume]$ vim jobs/file_to_kafka.conf -
配置文件内容如下:
# 1 组件定义 a1.sources = r1 a1.sinks = k1 a1.channels = c1# 2 配置source a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /opt/module/applog/app.* # 监控文件目录 a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json # offset文件 支持断点续传# 3 配置channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# 4 配置sink a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sinks.k1.kafka.topic = first a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.kafka.producer.linger.ms = 1# 5 拼接组件 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
-
-
启动 Flume
[atguigu@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f jobs/file_to_kafka.conf & -
向
/opt/module/applog/app.log里追加数据,查看 kafka 消费者消费情况[atguigu@hadoop102 module]$ mkdir applog [atguigu@hadoop102 applog]$ echo hello >> /opt/module/applog/app.log -
观察 kafka 消费者,能够看到消费的 hello 数据
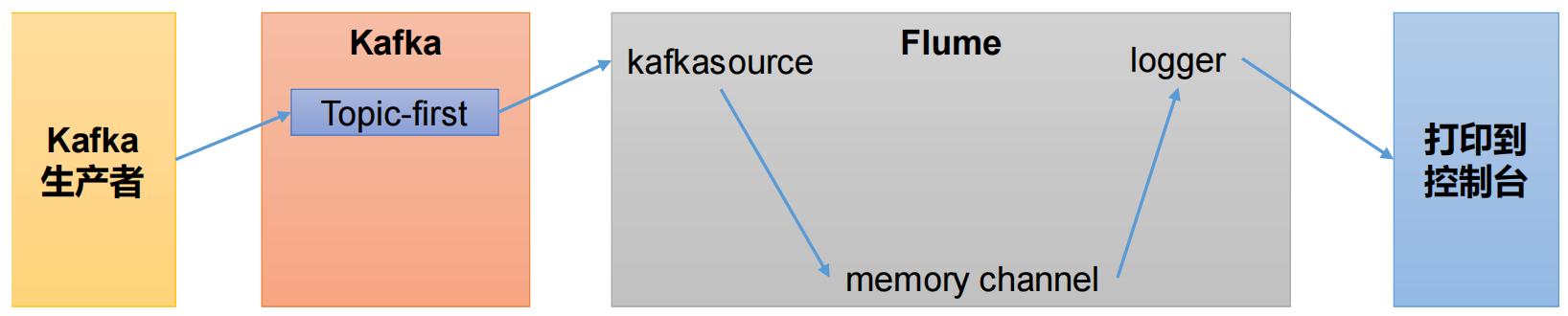
Flume 消费者
- Flume 作为消费者,首先肯定选用 kafka source
- 通道选择 memory channel
- 打印到控制台选择 logger sink
-
配置 Flume
-
在 hadoop102 节点的 Flume 的
/opt/module/flume/jobs目录下创建kafka_to_file.conf[atguigu@hadoop102 jobs]$ vim kafka_to_file.conf -
配置文件内容如下:
# 1 组件定义 a1.sources = r1 a1.sinks = k1 a1.channels = c1# 2 配置source a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.batchSize = 50 a1.sources.r1.batchDurationMillis = 200 a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092 a1.sources.r1.kafka.topics = first a1.sources.r1.kafka.consumer.group.id = custom.g.id# 3 配置channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# 4 配置sink a1.sinks.k1.type = logger# 5 拼接组件 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
-
-
启动 Flume
[atguigu@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f jobs/kafka_to_file.conf -Dflume.root.logger=INFO,console -
启动 kafka 生产者
[atguigu@hadoop103 kafka]$ bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first并输入数据,例如:hello
-
观察控制台输出的日志

Kafka 集成 Flink
Flink是一个在大数据开发中非常常用的组件,可以用于 Kafka 的生产者,也可以用于 Kafka 的消费者。
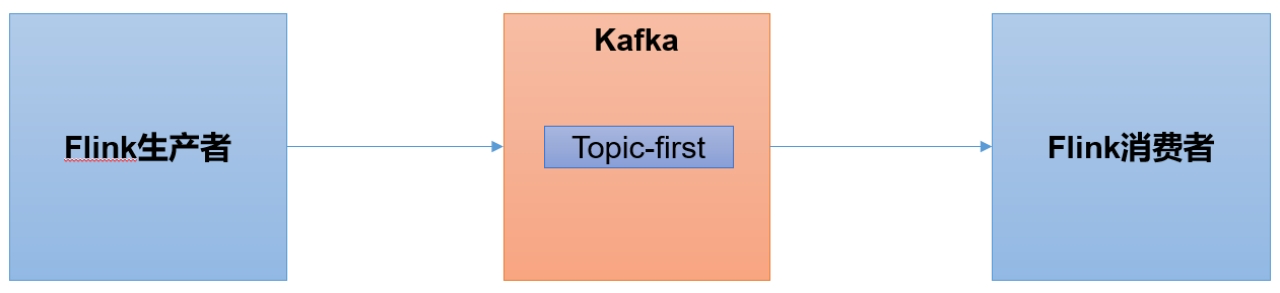
Flink 环境准备
-
创建一个 maven 项目
flink-kafka -
添加配置文件
<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.13.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>1.13.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>1.13.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>1.13.0</version></dependency> </dependencies> -
将 log4j.properties 文件添加到 resources 里面,就能更改打印日志的级别为 error
log4j.rootLogger=error, stdout,R log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%nlog4j.appender.R=org.apache.log4j.RollingFileAppender log4j.appender.R.File=../log/agent.log log4j.appender.R.MaxFileSize=1024KB log4j.appender.R.MaxBackupIndex=1log4j.appender.R.layout=org.apache.log4j.PatternLayout log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%6L) : %m%n -
在 java 文件夹下创建包名为
com.atguigu.flink
Flink 生产者
-
在
com.atguigu.flink包下创建 java 类:FlinkKafkaProducer1(系统也有一个 FlinkKafkaProducer,会重名,所以这里命名为 1)。import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig;import java.util.ArrayList; import java.util.Properties;public class FlinkKafkaProducer1 {public static void main(String[] args) throws Exception {// 0 初始化flink环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(3); // 3个槽 对应kafka主题题的3个分区// 1 准备数据源 读取集合中数据ArrayList<String> wordsList = new ArrayList<>();wordsList.add("hello");wordsList.add("atguigu");DataStream<String> stream = env.fromCollection(wordsList);// 2 kafka生产者配置信息Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// 3 创建kafka生产者FlinkKafkaProducer<String> kafkaProducer = new FlinkKafkaProducer<>("first",new SimpleStringSchema(), // 序列化和反序列化模板类 string类型properties);// 4 生产者和flink流关联stream.addSink(kafkaProducer);// 5 执行env.execute();} } -
启动Kafka消费者
[atguigu@hadoop104 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first -
执行
FlinkKafkaProducer1程序,观察 kafka 消费者控制台情况
Q:
- 为什么先接收到 atguigu,然后才是 hello 呢?
A:
- 在 Flink 中,对于并行度大于 1 的情况,不同的算子实例是并行运行的,也就是说当你的
env.setParallelism(3)时,会有3个线程同时运行。在你的例子中,"hello"和"atguigu"可能由不同的线程处理,并且处理的顺序是不确定的。 - 如果你希望严格按照顺序处理,你可以将并行度设置为
1,即env.setParallelism(1)。但是这样可能会影响处理速度。此外,Flink 也提供了一些方法来保证在并行处理时的顺序,可以查阅相关资料来了解更多。
Flink 消费者
-
在
com.atguigu.flink包下创建 java 类:FlinkKafkaConsumer1import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.common.serialization.StringDeserializer;import java.util.Properties;public class FlinkKafkaConsumer1 {public static void main(String[] args) throws Exception {// 0 初始化flink环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(3);// 1 kafka消费者配置信息Properties properties = new Properties();properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// group.id可选,不配置不会报错// 2 创建kafka消费者FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("first",new SimpleStringSchema(),properties);// 3 消费者和flink流关联env.addSource(kafkaConsumer).print();// 4 执行env.execute();} } -
启动
FlinkKafkaConsumer1消费者 -
启动 kafka 生产者
[atguigu@hadoop103 kafka]$ bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first -
观察 IDEA 控制台数据打印

有 3 个消费者并行消费,因为只发了两条消息,所以这里只有 1 和 3。
Kafka 集成 SpringBoot
SpringBoot 是一个在 JavaEE 开发中非常常用的组件。可以用于 Kafka 的生产者,也可以用于 SpringBoot 的消费者。
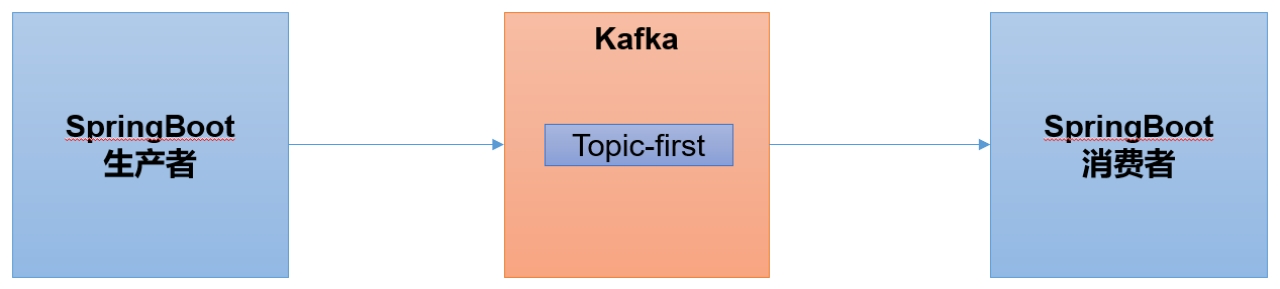
跟之前不太一样的是,外部数据是通过接口的方式发送到 SpringBoot 程序,然后 SpringBoot 接收到这个接口的数据,然后再发送到 kafka 集群。
SpringBoot 环境准备
-
在 IDEA 中安装
lombok插件在 Plugins 下搜索
lombok然后在线安装即可,安装后注意重启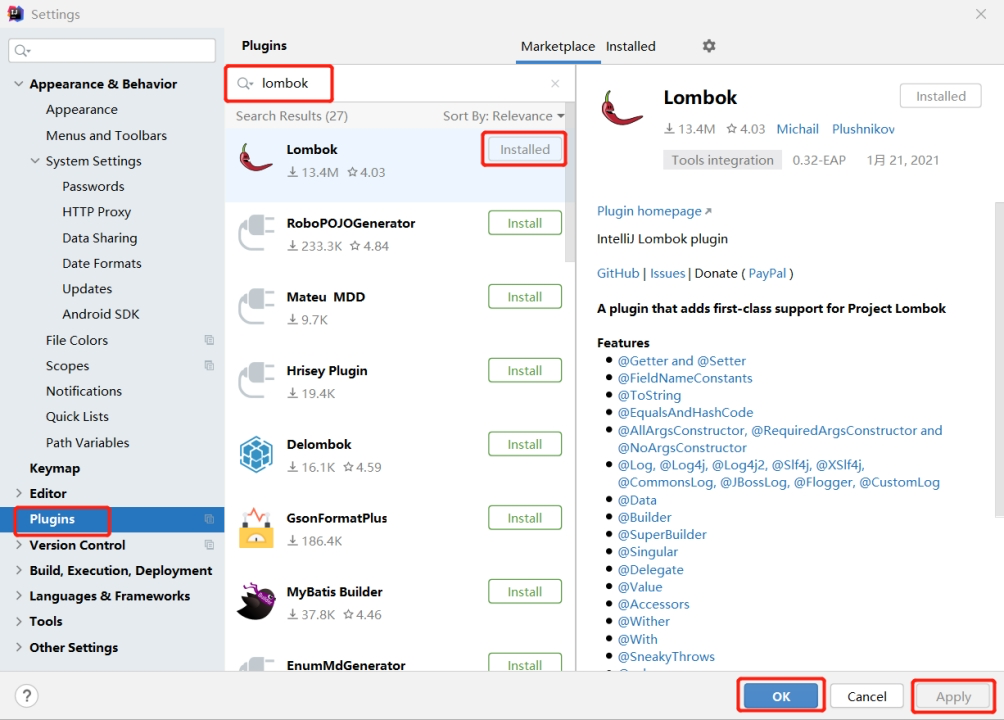
-
创建一个 Spring Initializr
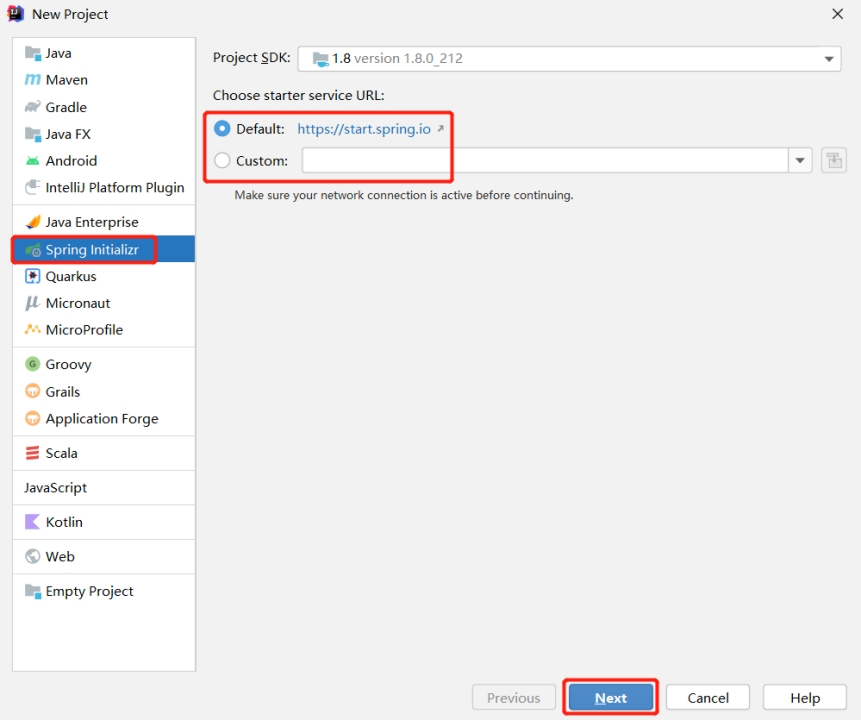
注意:有时候SpringBoot官方脚手架不稳定,我们切换国内地址:https://start.aliyun.com
-
项目名称 springboot
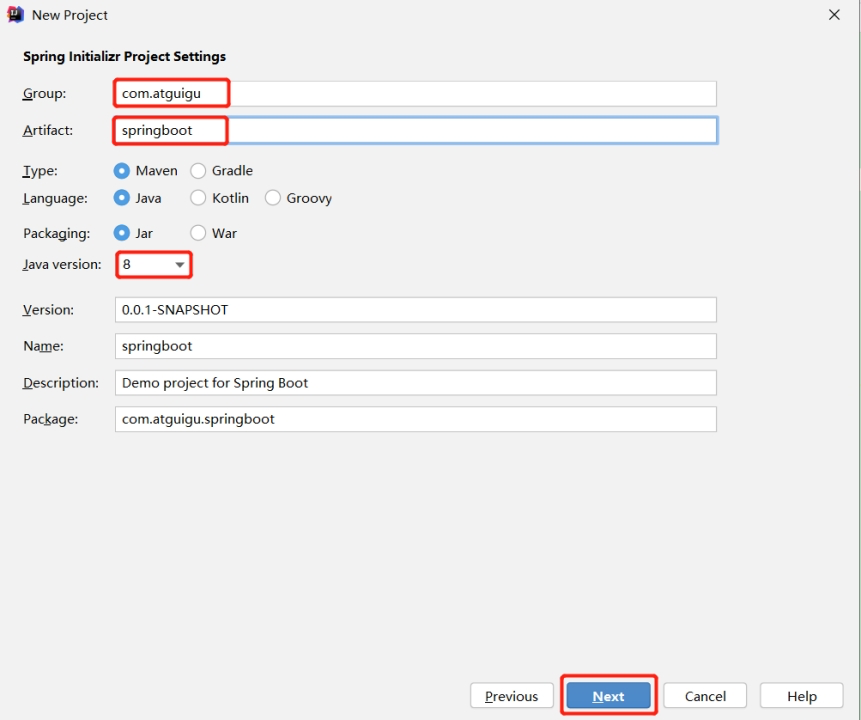
-
添加项目依赖
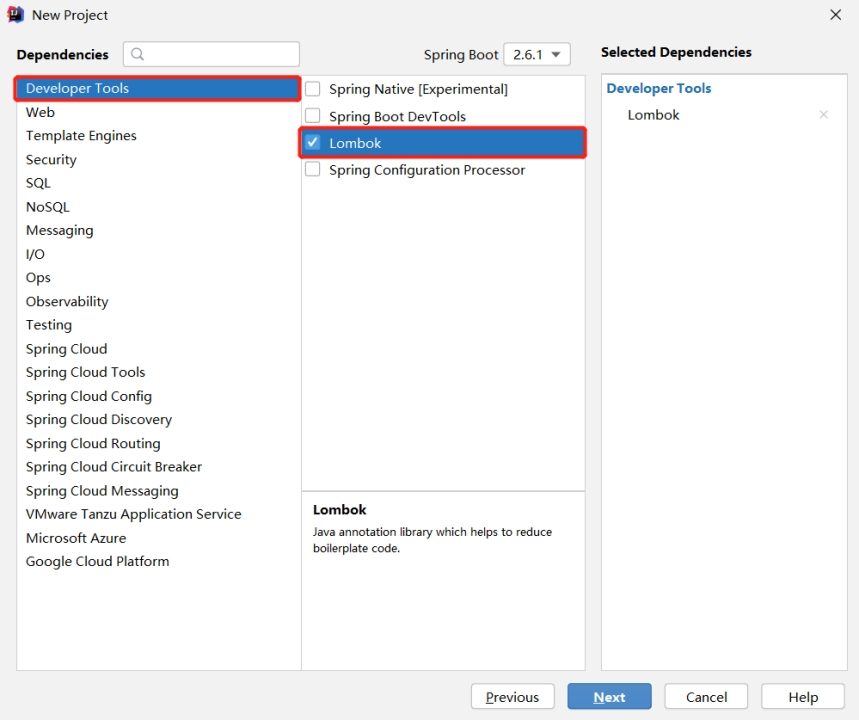
-
检查自动生成的配置文件
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.1</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.atguigu</groupId><artifactId>springboot</artifactId><version>0.0.1-SNAPSHOT</version><name>springboot</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>
SpringBoot 生产者
-
修改 SpringBoot 核心配置文件 application.propeties,添加生产者相关信息
# 应用名称 spring.application.name=atguigu_springboot_kafka# 指定kafka的地址 spring.kafka.bootstrap-servers=hadoop102:9092,hadoop103:9092,hadoop104:9092# 指定key和value的序列化器 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer -
创建 controller 从浏览器接收数据,并写入指定的 topic
import org.springframework.beans.factory.annotation.Autowired; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController;@RestController public class ProducerController {// Kafka模板用来向kafka发送数据@AutowiredKafkaTemplate<String, String> kafka;@RequestMapping("/atguigu")public String data(String msg) {kafka.send("first", msg);return "ok";} } -
在浏览器中给 /atguigu 接口发送数据
http://localhost:8080/atguigu?msg=hello
-
kafka 消费者接收到数据

SpringBoot 消费者
-
修改 SpringBoot 核心配置文件 application.propeties
# =========消费者配置开始========= # 指定kafka的地址 spring.kafka.bootstrap-servers=hadoop102:9092,hadoop103:9092,hadoop104:9092# 指定key和value的反序列化器 spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer# 指定消费者组的group_id spring.kafka.consumer.group-id=atguigu # =========消费者配置结束========= -
创建类消费 Kafka 中指定 topic 的数据
import org.springframework.context.annotation.Configuration; import org.springframework.kafka.annotation.KafkaListener;@Configuration public class KafkaConsumer {// 指定要监听的topic@KafkaListener(topics = "first")public void consumeTopic(String msg) { // 参数: 收到的valueSystem.out.println("收到的信息: " + msg);} } -
向 first 主题发送数据
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first > atguigu -
SpringBoot 消费者接收到数据

Kafka 集成 Spark
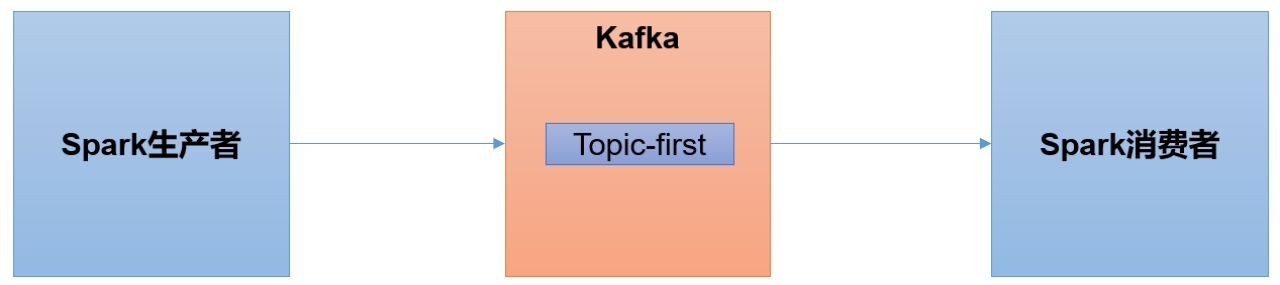
Spark 是一个在大数据开发中非常常用的组件,可以用于 Kafka 的生产者,也可以用于 Kafka 的消费者。
Spark 环境准备
-
Scala 环境准备
- 参考:P73 尚硅谷 Kafka 集成 Spark 生产者
Spark 的底层源码是用 Scala 编写的。
-
创建一个 maven 项目 spark-kafka
-
在项目 spark-kafka 上点击右键,Add Framework Support => 勾选
scala -
在 main 下创建 scala 文件夹,并右键 Mark Directory as Sources Root => 在 scala 下创建包名为 com.atguigu.spark
-
添加配置文件
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.0.0</version></dependency> </dependencies> -
将 log4j.properties 文件添加到 resources 里面,就能更改打印日志的级别为 error
log4j.rootLogger=error, stdout,R log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%nlog4j.appender.R=org.apache.log4j.RollingFileAppender log4j.appender.R.File=../log/agent.log log4j.appender.R.MaxFileSize=1024KB log4j.appender.R.MaxBackupIndex=1log4j.appender.R.layout=org.apache.log4j.PatternLayout log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%6L) : %m%n
Spark 生产者
-
在 com.atguigu.spark 包下创建
scala Object:SparkKafkaProducer
import java.util.Properties import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}object SparkKafkaProducer {def main(args: Array[String]): Unit = {// 0 kafka配置信息val properties = new Properties()properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092,hadoop104:9092")properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])// 1 创建kafka生产者var producer = new KafkaProducer[String, String](properties)// 2 发送数据for (i <- 1 to 5) {producer.send(new ProducerRecord[String, String]("first", "atguigu" + i))}// 3 关闭资源producer.close()} } -
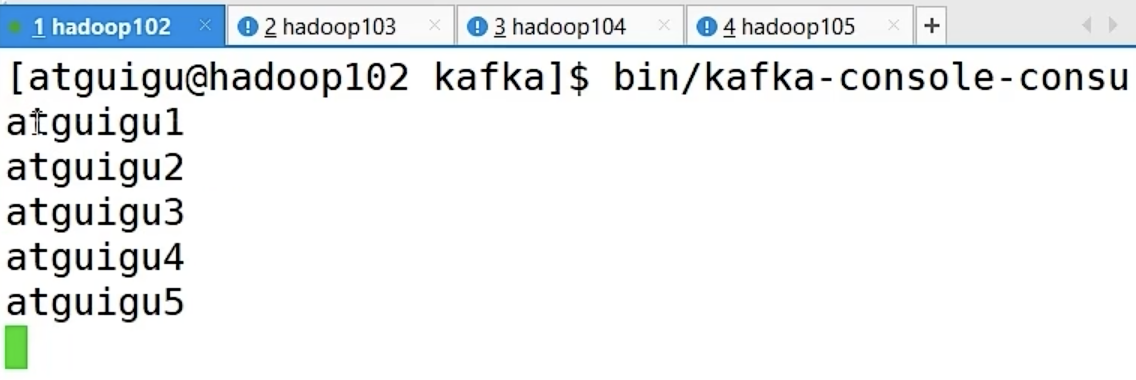
启动 Kafka 消费者
[atguigu@hadoop104 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first -
执行 SparkKafkaProducer 程序,观察 kafka 消费者控制台情况
Spark 消费者
-
添加配置文件
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.0.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.0.0</version></dependency> </dependencies> -
在 com.atguigu.spark 包下创建
scala Object:SparkKafkaConsumerimport org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord} import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, InputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}object SparkKafkaConsumer {def main(args: Array[String]): Unit = {// 1.创建SparkConfval sparkConf: SparkConf = new SparkConf().setAppName("sparkstreaming").setMaster("local[*]")// 2.创建StreamingContext 初始化上下文环境// Seconds(3):时间窗口,批处理间隔,表示每隔3秒钟,Spark Streaming就会收集一次数据进行处理。val ssc = new StreamingContext(sparkConf, Seconds(3))// 3.定义Kafka参数:kafka集群地址、消费者组名称、key序列化、value序列化val kafkaPara: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],ConsumerConfig.GROUP_ID_CONFIG -> "atguiguGroup")// 4.读取Kafka数据创建DStreamval kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc, // 上下文环境LocationStrategies.PreferConsistent, // 数据存储位置 优先位置ConsumerStrategies.Subscribe[String, String](Set("first"), kafkaPara) // 消费策略:(订阅多个主题,配置参数) )// 5.将每条消息的KV取出val valueDStream: DStream[String] = kafkaDStream.map(record => record.value())// 6.计算WordCountvalueDStream.print()// 7.开启任务 并阻塞(使程序一直执行)ssc.start()ssc.awaitTermination()} } -
启动 SparkKafkaConsumer 消费者
-
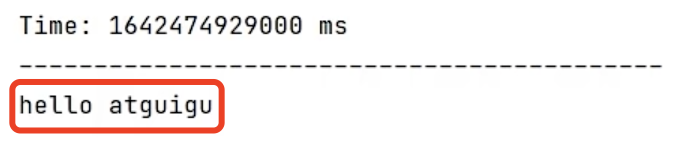
启动 kafka 生产者
[atguigu@hadoop103 kafka]$ bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first -
观察IDEA控制台数据打印
笔记整理自b站尚硅谷视频教程:【尚硅谷】Kafka3.x教程(从入门到调优,深入全面)