网站建设公司发展seo公司seo教程
系列文章目录
安装jmeter
jmeter常用配置元件介绍总结之后置处理器
- 8.后置处理器
- 8.1.CSS/JQuery提取器
- 8.2.JSON JMESPath Extractor
- 8.3.JSON提取器
- 8.4.正则表达式提取器
- 8.5.边界提取器
- 8.5.Debug PostProcessor
- 8.6.XPath2 Extractor
- 8.7.XPath提取器
- 8.8.结果状态处理器
8.后置处理器
后置处理器在采样器之后才执行
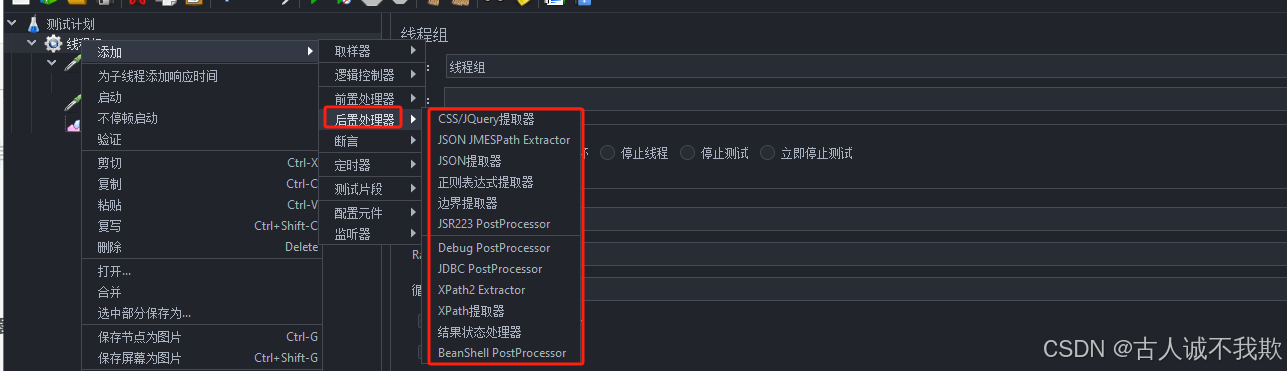
8.1.CSS/JQuery提取器
功能:主要用于要提取的目标内容是html内容时,如:请求响应消息返回的是html
参数介绍:
apply to:设置提取器,提取范围,从哪一部分提取数据
Main sample and sub-samples :匹配当前父级取样器,会覆盖字取样器
Main sample only:默认此选项,匹配当前父级取样器
Sub-samples only:匹配子取样器
JMeter Variable Name to use:在选项的输入框输入jmeter变量名,可以匹配jmeter变量值
提取相关参数配置:
CSS选择器提取器实现:选择提取方式,可以选择JSOUP/JODD,默认JSOUP
引用名称:设置变量名称,将提取到的值给到该变量
CSS选择器表达式:填写css选择器表达式
属性:填写属性名称,则提取对应属性的值,不填写则提取标签的text值
匹配数字(0代表随机):表示取提取到的第几个值,0:随机取值,-1:匹配所有,n:取第n个值
缺省值:设置一个默认值,没有提取到值时,就使用该值
如图提取text文本演示:


如图提取属性值演示:


8.2.JSON JMESPath Extractor
功能:以JMESPath表达式提取json格式的信息
参数介绍:
apply to:同上,CSS/JQuery提取器这里不再详细介绍
Names of created variables:设置变量名称,将提取到的值给到该变量
JESPath expressions:JESPath表达式
Match No. (0 for Random):表示取提取到的第几个值,0:随机取值,-1:匹配所有,n:取第n个值
Default Values:设置一个默认值,没有提取到值时,就使用该值
说明:
JESPath表达式基础介绍(这里只介绍了基本操作还有很多强大的功能):
1.用字段名来选择某一信息,如匹配msg值,就用表达式:msg,来匹配msg对应的值
2.用点·来表示子节点切换到子层级,如要匹配sub_msg值,就需要用到·,就用表达式:msg_all.sub_msg,来匹配sub_msg对应的值,多层则用.切进去即可
3.可以用数组下标取值,如:要取到值“测试2”,就用表达式remsg[1]
{"msg": "Business SUCCESS","code": "40004","sub_code": "ACQ.TRADE_HAS_SUCCESS","remsg": ["测试","测试2"],"msg_all": {"out_trade_no": "6823789339978248","sub_msg": "交易已被支付","trade_no": "2013112011001004330000121536"}
}
如图演示提取:


8.3.JSON提取器
功能:以JOSN Path表达式提取json格式的信息
参数介绍:
apply to:同上,CSS/JQuery提取器这里不再详细介绍
Names of created variables:设置变量名称
JSON Path expressions:JOSNPath表达式
Match No. (0 for Random):表示取提取到的第几个值,0:随机取值,-1:匹配所有,n:取第n个值
Compute concatenation var:匹配到多个值时,将多个值拼接起来,然后给设置的变量
Default Values:设置一个默认值
json path表达式基本介绍:
1.用$来表示根
2.用·来表示字节点
3.用[n],来通过下标取值
另外还可以配合一些常用操作符、通配符使用,如:==,>,<,*等
如:
取“测试”这个值:$.msg_all.remsg[0]
取sub_msg的值:$.msg_all.sub_msg
取code的值:$.code
{"msg": "Business SUCCESS","code": "40004","sub_code": "ACQ.TRADE_HAS_SUCCESS","msg_all": {"out_trade_no": "6823789339978248","sub_msg": "交易已被支付","remsg": ["测试","测试2"],"trade_no": "2013112011001004330000121536"}
}
如图:


另外这里介绍一个测试表达式的工具,
如图,在查看结果树中可以选择表达式类型,输入表达式进行测试

8.4.正则表达式提取器
功能:以正则表达式提取内容信息
参数介绍:
apply to:同上,CSS/JQuery提取器这里不再详细介绍
要检查的响应字段:设置从取样器的哪一部分提取内容。
分别表示:
主体:响应体,默认选中,最常用的
Body (unescaped):
Body as a Document
信息头:响应头
Request Headers:请求头
URL:URL
响应代码:响应码
响应信息:响应信息
引用名称:设置变量名称
正则表达式:填写正则表达式
正则表达式基础应用讲解:
():用括号括起来的部分就表示要提取的内容
.:点表示任意字符
+:加表示匹配一次或多次
?:问号表示第一个匹配项找到后停止匹配
:星号表示匹配字符任意次
使用的格式:左边界(.?)有边界
一般常用的有(.*?)、(.+?)能满足绝大部分情况
模板:设置匹配的字符串模板模板
匹配数字(0代表随机):表示取提取到的第几个值,0:随机取值,-1:匹配所有,n:取第n个值
缺省值:设置一个默认值
{"msg": "Business SUCCESS","code": "40004","sub_code": "ACQ.TRADE_HAS_SUCCESS","msg_all": {"out_trade_no": "6823789339978248","sub_msg": "交易已被支付","remsg": ["测试","测试2"],"trade_no": "2013112011001004330000121536"}
}
如图提取单个值演示:


如图提取多个值演示:


注意:
1.同时提取多个值时,引用名称只需要设置一个
2.模板提取多少变量就应该设置几个模板,多个模板之间用分隔符隔开
3.提取多个值时通过${变量名+_gn},如:我这里演示的引用第一个值就用${test_g1}依次类推,
4.提取单值,一个引用名、一个模板、直接引用变量名即可
提示:
有个小技巧就是直接复制要提取的内容把要匹配的值换位(.*?),大部分情况可直接使用。
如要提取以上测试内容的:“交易已被支付”
先复制:“sub_msg”:“交易已被支付”,“trade_no”
替换内容:“sub_msg”:“(.*?)”,“trade_no”
8.5.边界提取器
功能:以边界的方式式提取内容信息
参数介绍:
apply to和要检查的响应字段就不做过多介绍了文章前面其他元件有介绍
引用名称:设置变量名称
左边界:设置左边界内容,从提取内容开始前的边界
右边界:设置右边界的内容,从提取内容开始后的边界
匹配数字(0代表随机):表示取提取到的第几个值,0:随机取值,-1:匹配所有,n:取第n个值
缺省值:设置一个默认值


8.5.Debug PostProcessor
主要用于调试JMeter 属性、取样器属性、系统属性中的参数,在查看结果树中查看返回的值
如图:


8.6.XPath2 Extractor
功能:用xpath表达式来提取html内容
参数介绍:
引用名称:设置变量名称
XPath query:xpath表达式,xpath语法这里暂时不做介绍
匹配数字(0代表随机):表示取提取到的第几个值,0:随机取值,-1:匹配所有,n:取第n个值
缺省值:设置一个默认值
Return entire XPath fragment instead of text content?:勾选后会连带内容所在的标签也返回来


8.7.XPath提取器
功能:用xpath表达式来提取内容
参数介绍:
XML Parsing Options:解析的XML参数配置
UseTidy:页面是HTML格式时,选中该选项;如果是XML或XHTML格式,则取消选中
Quiet:只显示需要的HTML页面
Report errors:显示响应报错
Show warnings:显示警告;
Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨;
Validate XML:根据页面元素模式进行检查解析;
Ignore Whitespace:忽略空白内容
Return entire XPath fragment instead of text content?:勾选后会连带内容所在的标签也返回来
引用名称:设置变量名称
XPath query:xpath表达式,xpath语法这里暂时不做介绍
匹配数字(0代表随机):表示取提取到的第几个值,0:随机取值,-1:匹配所有,n:取第n个值
缺省值:设置一个默认值


8.8.结果状态处理器
功能:主要用来监听取样器执行失败后的结果状态,配置执行失败后执行怎么处理,失败后执行什么动作,如:失败后继续、失败后停止测试等
