独立程序员做网站百度seo排名培训优化
Beautiful Soup网站:https://www.crummy.com/software/BeautifulSoup/
作用:它能够对HTML.xml格式进行解析,并且提取其中的相关信息。它可以对我们提供的任何格式进行相关的爬取,并且可以进行树形解析。
使用原理:它能够把任何我们给它的文档当作一锅汤,任何给我们煲制这锅汤。
一、安装
目前最常用的版本是Beautiful Soup 4,也就是 bs4 ,所以在导入时 import bs4就是在导入Beautiful Soup
1.使用管理员权限打开command命令台
2.运行pip install beautifulsoup4
二、Beautiful Soup的安装小测
以下链接为测试链接:This is a python demo page (python123.io)
1.打开该链接查看页面

2.浏览器打开页面后,右击打开“查看页面源代码”(edge,其他浏览器也可),任何将源代码拷贝下来放在我们的程序当中,或者使用上一博文所说的requests库。r.text就是html代码相关的内容。

3.为了简化,我们可以定义一个变量叫做demo,表示这个页面的所有代码的内容
![]()
4.导入beautiful soup库:from bs4 import BeautifulSoup
5.除了给出html,还要给出解析demo的解释器:soup= BeautifulSoup(demo,"html.parser")
6.看看安装是否正确:print(soup.prettify())

三、Beautiful Soup库的基本元素
Beautiful Soup库也叫beautifulsoupb4或bs4。bs4库是解析、遍历、维护“标签树”的功能库,只要我们提供的文件是标签类型,那么bs库都能给它做很好的解析。

这个属性是用来定义标签的特点的。
bs库的引用:from bs4 import BeautifulSoup。这说明我们从bs库引入了一个BeautifulSoup模型。如果我们需要bs库里面的一些基本变量进行判断的时候,我们可以直接引用bs库:import bs4.
理解bs:bs本身解析的是html和xml文档,那么这个文档和标签树是一一对应的,那么经过了bs类的处理(把标签树理解为一个字符串,bs就可以把它转化为一个bs类,bs类是一个能代表标签树的类型。)事实上,我们认为html文档,标签树和bs类这三者是等价的,bs对应一个html/xml文档的全部内容。

实际上,每一种解析器它都是可以有效解析html和xml文档的,这里面我们主要使用的是html解析器。




这时候,soup表示我们解析后的demo页面。title标签就是我们页面在浏览器左上方显示位置信息的地方。事实上,所有html语法上的标签都可以使用soup.tag方式访问获得。

当html文档中存在多个相同的tag标签时,我们用soup.tag只能返回其中的第一个。比如刚刚访问的a标签,页面中有两个a标签,却只返回第一个。
获取标签名字的方法:

a.parent表示包裹a的上一级标签。

标签的属性是在标签中标明标签特点的相关区域,它以字典的形式来组织。因为它是字典,我们可以对属性做信息的提取,如下图。

查看标签属性的类型:type(tag.attrs)

需注意,tag标签可以有零个或者多个属性,那么如果没有属性存在的时候,我们使用attrs获得的字典是个空字典,但是无论有属性还是没有属性,我们总能获得一个字典。
获得标签之间的内容:

注释:

我们分别对p和b标签分别用.string的时候,我们都能产生一段文本,但是当这个文本是注释形式的时候,它并没有标明它是注释,所以我们分析文档的时候,我们需要对其中的注释部分做相关的判断,而判断的依据就是它的类型,这种情况在我们分析文本中并不常用,所以做一个基本了解即可。
四、基于bs库的html内容遍历方法
遍历方式:上行遍历、下行遍历、平行遍历
1.下行遍历


对于一个标签的儿子节点并不仅仅包括标签节点,也包括字符串节点,比如像是\n的回车,它也是一个body标签的儿子节点类型,我们可以用len函数获得儿子节点的数量,或者给定数组下标获得对应数据。


2.上行遍历


soup的父亲是空的。
上行遍历代码如下:

3.平行遍历
使用条件:平行遍历发生在同一个付节点的各节点间,不是同一个父节点下的标签之间不构成平行遍历关系。


需注意,在标签树中,尽管数形结构采用的是标签的形式来组织,但是标签之间的navigableString也构成了标签树的节点,也就是说任何一个节点它的平行标签,它的父亲标签,它的儿子标签是可能存在navigableString类型的。
平行遍历代码如下:

总结:

五、基于bs库的html格式化和编码
1.格式化
目的:让html内容更加友好的显示
方案:利用BS库的prettify()方法
prettify()作用:能够为html文本的标签以及内容增加换行符,它也可以对每一个标签来做相关的处理


2.编码
注意,bs4库将任何读入的html文件或者字符串都转换成utf-8编码
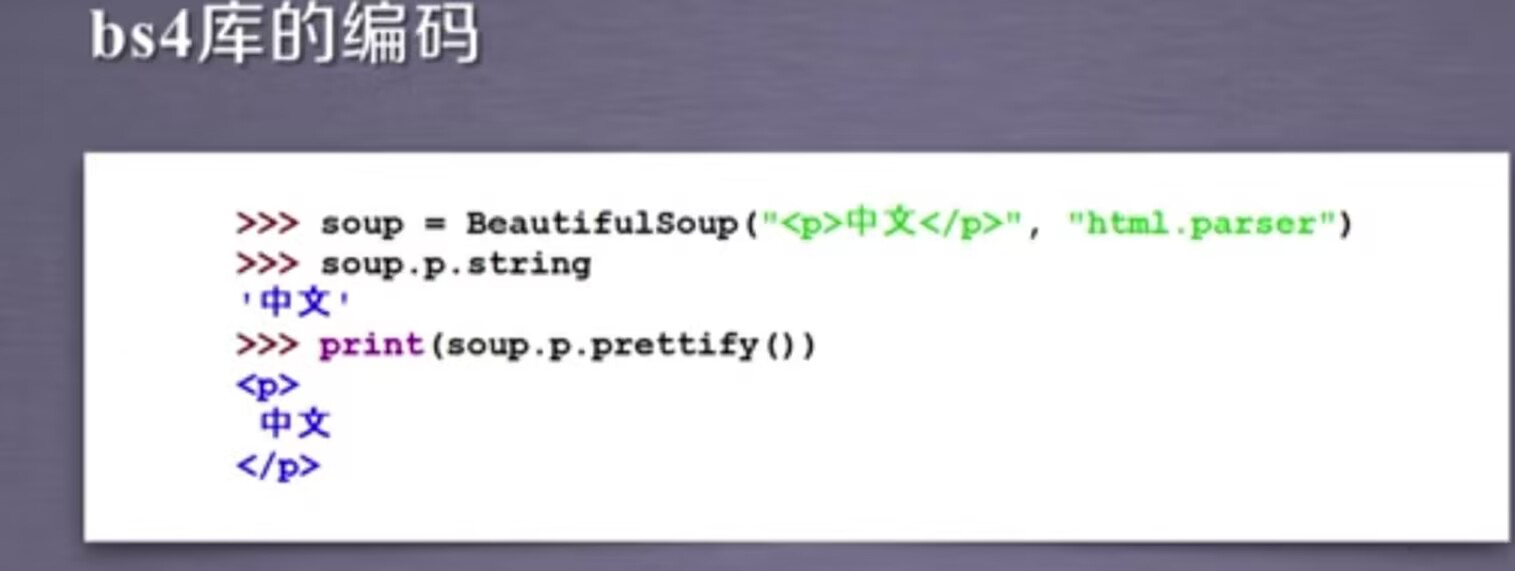
可以看见,当我们输入中文的时候,它的结果可以很好的显示出来。
六、信息标记的三种形式
作用:1.标记后的信息可形成信息组织结构,增加信息维度 2.标记后的信息可用于通讯、存储和展示 3.标记的结构与信息用于具有价值 4.标记后的信息更有利于程序理解和运用
HTML的信息标记:HTML是WWW的信息组织方式,可以把声音图像视频等超文本的信息嵌入到文本当中。HTML通过预定义的<>...</>标签形式组织不同类型的信息
现在国际公认的三种信息标记种类:xml、ison、yaml
1.xml
xml,拓展标记语言,与html很接近的标记语言,它采用了以标签为主来构建信息和表达信息。


2.json
json,有类型的键值对 key:value。当一个键值有多个值时,采用[]和逗号隔开。
好处:对于javascript等编程语言来说,可以直接将json格式作为程序的一部分,简化编程。


3.yaml
yaml,无类型的键值对 key:value。通过缩进表示包含关系。



七、三种信息标记形式的比较
表示形式



实例



xml:有效信息占比不高,大多数信息被标签占用
比较


八、信息的提取的一般方法

方法一: 我们需要什么信息,去解析标签树就可以了。好处是你需要什么信息,就能找到这部分的位置。缺点是需要对整个文件的信息组织形式有清楚的认识和理解

方法二:就好像我们使用word一样,根本不需要关心整个word文档具有什么样的标题形式和格式,只需要我们对信息的文本利用函数去查找就可以。

实例:提取HTML中所有URL链接
思路:1.搜索到所有<a>标签 2.解析<a>标签格式,提取href后的链接内容。

九、基于bs4库的html内容查找方法


如果我们给出的标签名是true的话,将显示当前soup的所有标签信息。
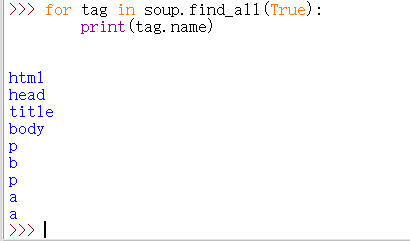
当我们需要查询b开头的b和body标签,这需要我们引入正则表达式库(import re)。

soup.find_all(id='link1')表示包含的元素就是属性中id域等于link1的标签元素,当查找的内容html不包含时,则返回空数组。

也就是当进行属性查找的时候,我们必须准确地赋值这个信息,如果我们想查找属性的部分信息,可以考虑引入正则表达式,否则就需要准确查找,不多也不能少。

soup.find_all('a',recursive=False)返回空值,表示它的儿子节点层面上是没有a标签的

查找更多信息 :

简写方式:
<tag>(..) 等价于 <tag>.find_all(..)
soup(..) 等价于 soup.find_all(..)
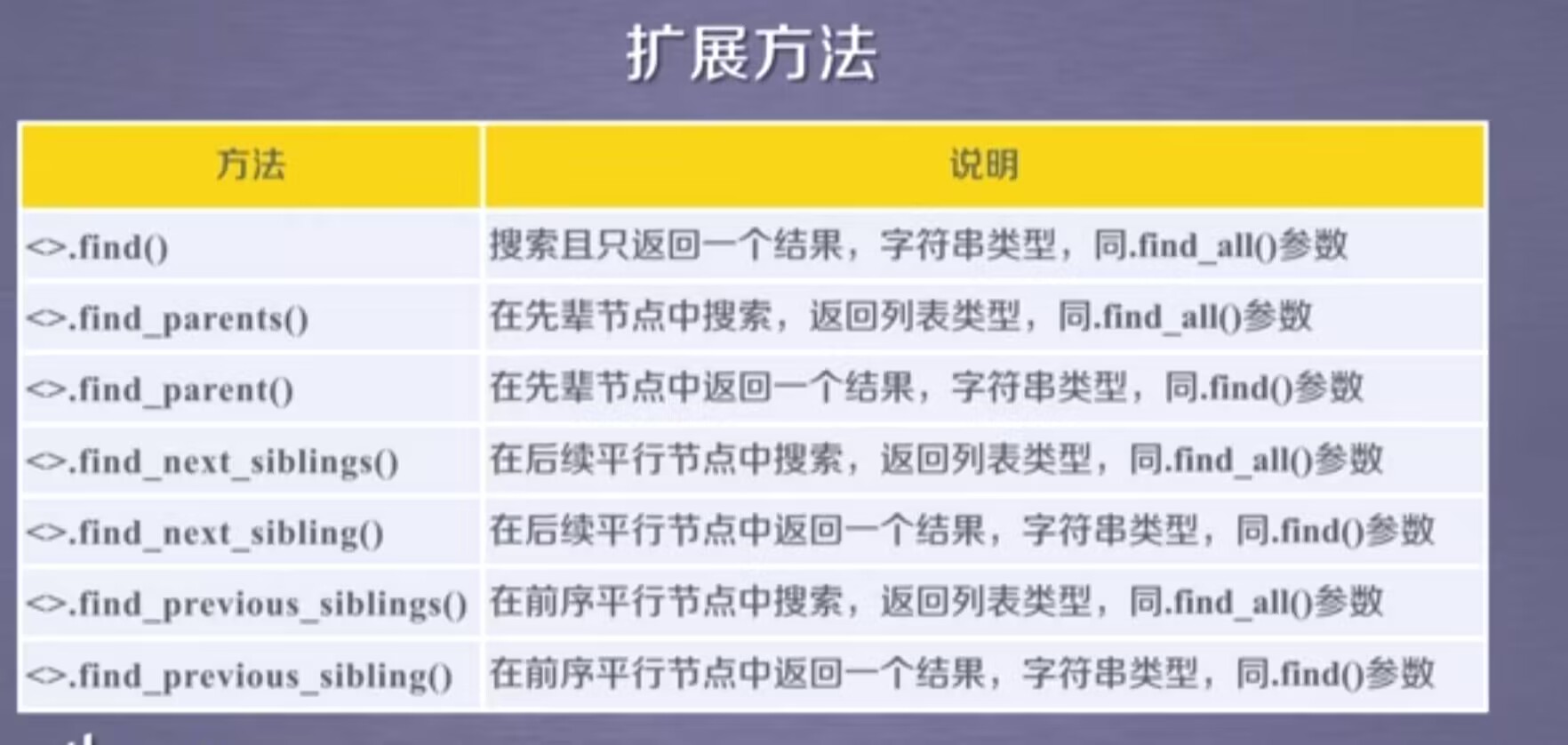
扩展方法:
十、实例:中国大学排名定向爬虫
基本情况:我们将采取由上海交通大学设计研发的最好大学排名。
【软科排名】2023年最新软科中国大学排名|中国最好大学排名 (shanghairanking.cn)
功能描述:
输入:大虚的排名URL链接
输出:排名、名称、总分
技术路线:requests-bs4
定向爬虫:仅对输入url进行爬取,不拓展爬取其他url。
注意:如果有些数据是通过javascript等脚本语言生成的,也就是说当你访问一个网页的时候,它的信息是动态提取和生成的,在这种情况下,用requests和bs4是无法获取它的信息的。
程序的结构设计与(步骤):1.从网络上获取大学排名网页内容(可以定义一个getHTMLText()函数) 2.提取网页内容中信息到合适的数据结构(定义fillUnivList()) 3.利用数据结构展示并输出结果(定义printUnivList())
实现:
(关于在IDLE中怎么换行继续敲写代码而不执行语句 :按ctrl+n弹出新窗口,在新窗口里面写。)
先写主函数,由于实现了网络请求,我们要import requests库和bs4库![]()
刚才我们定义了三个函数分别对应三个步骤,我们将这三个函数写进来,但由于此时我们还没有对每个函数的内部功能进行设计和实现,所以我们只要写出函数的定义就可以。pass语句表示不做任何操作。

我们将大学信息放在unifo中,给出刚刚页面的链接https://www.shanghairanking.cn/rankings/bcur/202311
然后调用刚刚的三个函数,先将url转换成html,然后信息提取后将html放在unifo中
接着填充第一个函数:设置timeout时间是30秒,然后用raise_for_status来产生异常信息,接着修改编码,然后把网页内容返回给程序的其他部分。

接着填充第二个函数:通过BeautifulSoup库解析网页,将需要的信息加入到一个列表中。if isinstance(tr, bs4.element.Tag): 判断tr标签是不是bs4定义的tag标签,过滤掉不是bs4定义的tag标签,为了使这个代码能够运行,我们需引入一个叫bs4的库
所有代码如下:
import requests
import bs4
from bs4 import BeautifulSoup
def getHTMLText(url):try:r = requests.get(url,timeout=30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:return ""def fillUnivList(ulist,html):soup = BeautifulSoup(html, "html.parser")for tr in soup.find("tbody").children:if isinstance(tr, bs4.element.Tag): tds = tr('td') n = tds[1].find("a").string # 因为大学名字在td标签的子标签a中,所以需要单独提取ulist.append([tds[0].string, n, tds[4].string])def printUnivList(ulist,num):tplt = "{0:^10}{1:{3}^10}{2:^10}"print(tplt.format("序号", "学校名称", "总分", chr(12288))) for i in range(num):u = ulist[i]a = u[0].strip() # 去掉字符串类两边的空格b = u[1].strip()c = u[2].strip()print(tplt.format(a, b, c, chr(12288)))def main():unifo=[]url='https://www.shanghairanking.cn/rankings/bcur/202311'html=getHTMLText(url)fillUnivList(unifo,html)printUnivList(unifo,20)main()
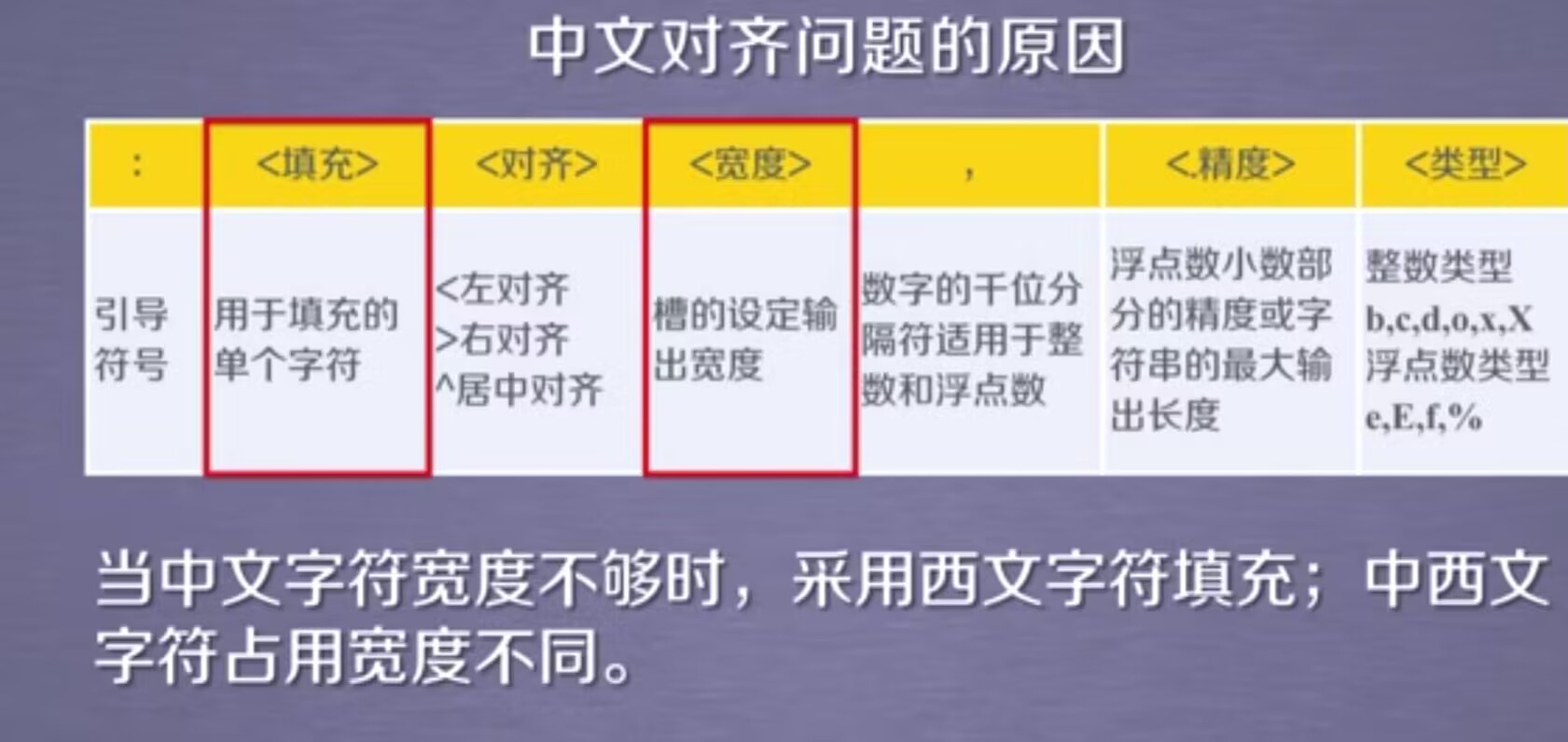
美化:采用中文字符的空格进行填充--chr(12288)