滨州聊城网站建设全网营销一站式推广
文章目录
- 1.业务场景与任务调度
- 2.任务调度的基本实现
- 2.1 多线程方式实现
- 2.2 Timer方式实现
- 2.3 ScheduledExecutor方式实现
- 2.4 第三方Quartz方式实现
- 3.分布式任务调度
- 4.XXL-JOB介绍
- 5.搭建XXL-JOB —— 调度中心
- 5.1 下载与查看XXL-JOB
- 5.2 创建数据库表
- 5.3 修改默认的配置信息
- 5.4 启动服务程序
- 5.5 访问调度中心控制台
- 6.搭建XXL-JOB —— 执行器
- 6.1 pom.xml核心配置
- 6.2 application.yaml核心配置
- 6.3 XxlJobConfig配置类
- 6.4 XxlJobDemoApplication启动类
- 6.5 进入调度中心添加执行器
- 7.搭建XXL-JOB —— 执行任务
- 7.1 简单任务示例(Bean模式)
- 7.1.1 编写任务方法
- 7.1.2 在调度中心进行任务管理
- 7.2 调度策略
- 7.3 分片广播
- 7.3.1 编写任务方法
- 7.3.2 增加一个节点服务
- 7.3.3 调度中心-执行器管理
- 7.3.4 调度中心-新增与启用任务
- 7.3.5 校验任务
- 7.4 高级配置说明
- 7.4.1 子任务
- 7.4.2 调度过期策略
- 7.4.3 阻塞处理策略
- 7.4.4 任务超时时间
- 7.4.5 失败重试次数
- 8.作业分片方案
- 9.三个经典面试题
- 9.1 xxl-jobo是怎么工作的?
- 9.2 如何保证任务不重复执行?
- 9.3 如何保证任务处理的幂等性?
❓ 如何去高效处理一批任务
分布式任务调度的处理方案:分布式加多线程,充分利用多台计算机,每台计算机使用多线程处理。
1.业务场景与任务调度
我们可以先思考一下下面业务场景的解决方案:
- 某电商系统需要在每天上午10点,下午3点,晚上8点发放一批优惠券。
- 某财务系统需要在每天上午10点前结算前一天的账单数据,统计汇总。
- 某电商平台每天凌晨3点,要对订单中的无效订单进行清理。
- 12306网站会根据车次不同,设置几个时间点分批次放票。
- 电商整点抢购,商品价格某天上午8点整开始优惠。
- 商品成功发货后,需要向客户发送短信提醒。
类似的场景还有很多,我们该如何实现?以上这些场景,就是任务调度所需要解决的问题。
📖 任务调度顾名思义,就是对任务的调度,它是指系统为了完成特定业务,基于给定时间点,给定时间间隔或者给定执行次数自动执行任务。
2.任务调度的基本实现
2.1 多线程方式实现
我们可以开启一个线程,每sleep一段时间,就去检查是否已到预期执行时间。
以下代码简单实现了任务调度的功能:
/*** @author 狐狸半面添* @create 2023-02-16 13:15*/
public class ThreadTaskDemo {public static void main(String[] args) {// 指定任务执行间隔时间(单位:ms)final long timeInterval = 1000;Runnable runnable = new Runnable() {public void run() {while (true) {// TODO 需要执行的任务System.out.println("多线程方式任务调度:每隔1s执行一次任务");try {Thread.sleep(timeInterval);} catch (InterruptedException e) {e.printStackTrace();}}}};Thread thread = new Thread(runnable);// 线程执行,开启定时任务thread.start();}
}
上面的代码实现了按一定的间隔时间执行任务调度的功能。
Jdk也为我们提供了相关支持,如Timer、ScheduledExecutor,如下👇
2.2 Timer方式实现
Timer 的优点在于简单易用,每个Timer对应一个线程,因此可以同时启动多个Timer并行执行多个任务,同一个Timer中的任务是串行执行。
import java.util.Timer;
import java.util.TimerTask;/*** @author 狐狸半面添* @create 2023-02-17 15:18*/
public class TimerTaskDemo {public static void main(String[] args) {Timer timer = new Timer();// 1秒后开始任务调度,每2秒执行一次任务timer.schedule(new TimerTask() {@Overridepublic void run() {// TODO 需要执行的任务System.out.println("Timer方式任务调度:每隔2s执行一次任务");}}, 1000, 2000);}
}
2.3 ScheduledExecutor方式实现
Java 5 推出了基于线程池设计的 ScheduledExecutor,其设计思想是,每一个被调度的任务都会由线程池中一个线程去执行,因此任务是并发执行的,相互之间不会受到干扰。需要注意的是,只有当任务的执行时间到来时,ScheduedExecutor 才会真正启动一个线程,其余时间 ScheduledExecutor 都是在轮询任务的状态。
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;/*** @author 狐狸半面添* @create 2023-02-17 15:22*/
public class ScheduledExecutorTaskDemo {/*** 设置线程池的线程数量*/private static ScheduledExecutorService executor = Executors.newScheduledThreadPool(3);public static void main(String[] args) {// 第一个任务调度executor.scheduleAtFixedRate(// 可以使用匿名内部类方式创建一个Runnable实现类,也可以new一个类实现Runnable接口new Runnable() {@Overridepublic void run() {// todo 需要执行的任务System.out.println("任务一 定时调度中");}},// 0秒后开始任务调度,每隔1秒执行一次任务0, 1, TimeUnit.SECONDS);// 第二个任务调度executor.scheduleAtFixedRate(// 可以使用匿名内部类方式创建一个Runnable实现类,也可以new一个类实现Runnable接口new Task(),// 500毫秒后开始任务调度,每隔2000毫秒执行一次任务500, 2000, TimeUnit.MILLISECONDS);}static class Task implements Runnable {@Overridepublic void run() {// todo 需要执行的任务System.out.println("任务二 定时调度中");}}
}
2.4 第三方Quartz方式实现
Timer 和 ScheduledExecutor 都仅能提供基于开始时间与重复间隔的任务调度,对于比较复杂的调度需求,比如,设置每月第一天凌晨1点执行任务、复杂调度任务的管理、任务间传递数据等等,实现起来比较麻烦。
Quartz 是一个功能强大的任务调度框架,它可以满足更多更复杂的调度需求,Quartz 设计的核心类包括 Scheduler, Job 以及 Trigger。其中,Job 负责定义需要执行的任务,Trigger 负责设置调度策略,Scheduler 将二者组装在一起,并触发任务开始执行。Quartz支持简单的按时间间隔调度、还支持按日历调度方式,通过设置CronTrigger表达式(包括:秒、分、时、日、月、周、年)进行任务调度。
<!-- https://mvnrepository.com/artifact/org.quartz-scheduler/quartz -->
<dependency><groupId>org.quartz-scheduler</groupId><artifactId>quartz</artifactId><version>2.3.2</version>
</dependency>
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;/*** @author 狐狸半面添* @create 2023-02-17 15:47*/
public class QuartzDemo {public static void main(String[] agrs) throws SchedulerException {// 创建一个SchedulerSchedulerFactory schedulerFactory = new StdSchedulerFactory();Scheduler scheduler = schedulerFactory.getScheduler();// 创建JobDetailJobBuilder jobDetailBuilder = JobBuilder.newJob(MyJob.class);jobDetailBuilder.withIdentity("jobName", "jobGroupName");JobDetail jobDetail = jobDetailBuilder.build();// 创建触发的CronTrigger 支持按日历调度CronTrigger trigger = (CronTrigger) TriggerBuilder.newTrigger().withIdentity("triggerName", "triggerGroupName").startNow()// 每隔两秒执行一次.withSchedule(CronScheduleBuilder.cronSchedule("0/2 * * * * ?")).build();//创建触发的SimpleTrigger 简单的间隔调度/*SimpleTrigger trigger = TriggerBuilder.newTrigger().withIdentity("triggerName","triggerGroupName").startNow().withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(2).repeatForever()).build();*/scheduler.scheduleJob(jobDetail, (Trigger) trigger);scheduler.start();}public static class MyJob implements Job {@Overridepublic void execute(JobExecutionContext jobExecutionContext) {// todo 需要定时调度的任务System.out.println("定时任务正在调度执行");}}
}
3.分布式任务调度
通常任务调度的程序是集成在应用中的,比如:优惠卷服务中包括了定时发放优惠卷的的调度程序,结算服务中包括了定期生成报表的任务调度程序,由于采用分布式架构,一个服务往往会部署多个冗余实例来运行我们的业务,在这种分布式系统环境下运行任务调度,我们称之为分布式任务调度,如下图:

🚩 分布式调度要实现的目标:
不管是任务调度程序集成在应用程序中,还是单独构建的任务调度系统,如果采用分布式调度任务的方式就相当于将任务调度程序分布式构建,这样就可以具有分布式系统的特点,并且提高任务的调度处理能力:
并行任务调度:并行任务调度实现靠多线程,如果有大量任务需要调度,此时光靠多线程就会有瓶颈了,因为一台计算机CPU的处理能力是有限的。
如果将任务调度程序分布式部署,每个结点还可以部署为集群,这样就可以让多台计算机共同去完成任务调度,我们可以将任务分割为若干个分片,由不同的实例并行执行,来提高任务调度的处理效率。高可用:若某一个实例宕机,不影响其他实例来执行任务。弹性扩容:当集群中增加实例就可以提高并执行任务的处理效率。任务管理与监测:对系统中存在的所有定时任务进行统一的管理及监测。让开发人员及运维人员能够时刻了解任务执行情况,从而做出快速的应急处理响应。避免任务重复执行:当任务调度以集群方式部署,同一个任务调度可能会执行多次,比如在上面提到的电商系统中到点发优惠券的例子,就会发放多次优惠券,对公司造成很多损失,所以我们需要控制相同的任务在多个运行实例上只执行一次。
4.XXL-JOB介绍
XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
🏠 官网:https://www.xuxueli.com/xxl-job/
📖 文档:https://www.xuxueli.com/xxl-job/#%E3%80%8A%E5%88%86%E5%B8%83%E5%BC%8F%E4%BB%BB%E5%8A%A1%E8%B0%83%E5%BA%A6%E5%B9%B3%E5%8F%B0XXL-JOB%E3%80%8B
XXL-JOB主要有调度中心、执行器、任务:
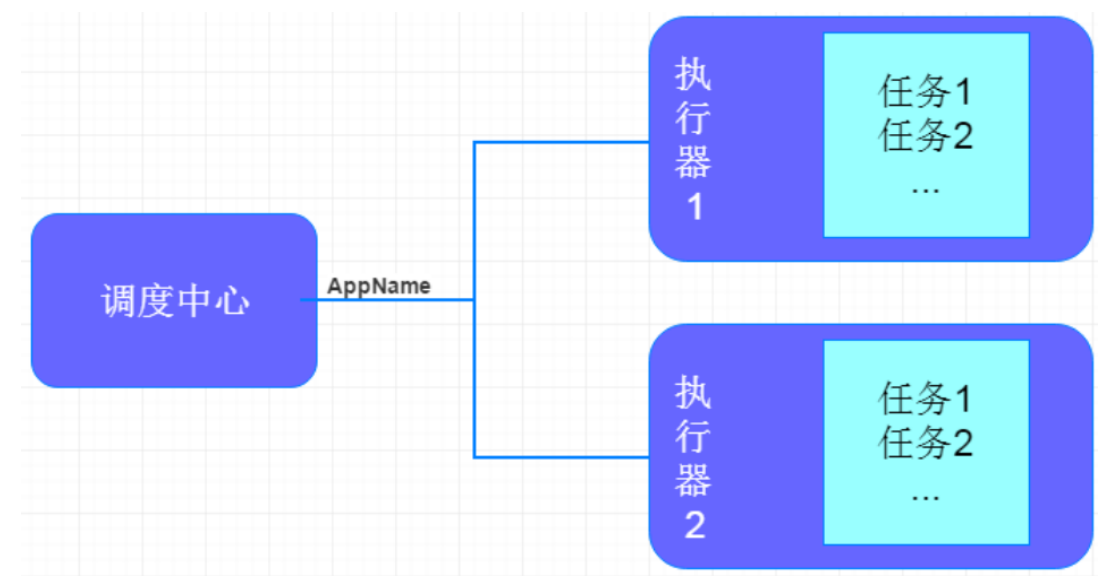
🍀 调度中心:负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。主要职责为执行器管理、任务管理、监控运维、日志管理等。
🍀 任务执行器:负责接收调度请求并执行任务逻辑。只要职责是注册服务、任务执行服务(接收到任务后会放入线程池中的任务队列)、执行结果上报、日志服务等。
🍀 任务:负责执行具体的业务处理。
🚩 调度中心与执行器之间的工作流程如下:
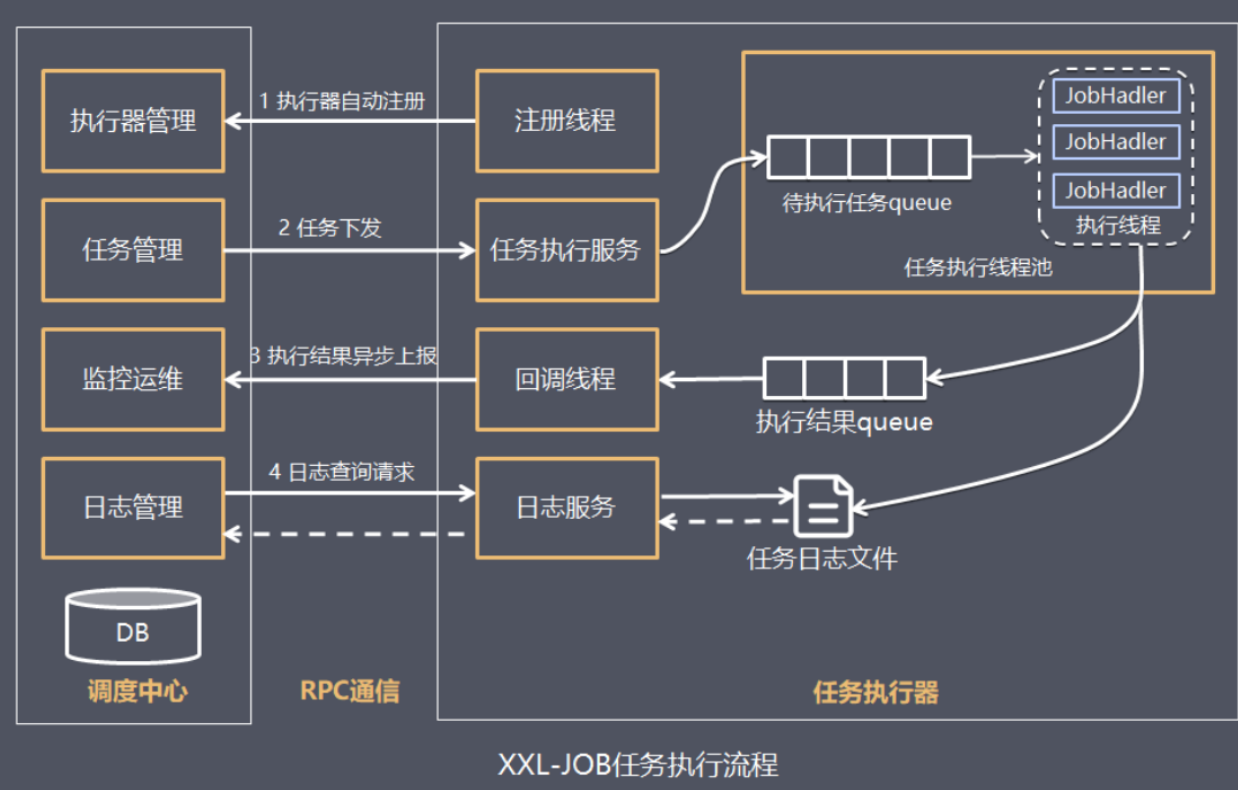
📍 执行流程:
- 任务执行器根据配置的调度中心的地址,自动注册到调度中心。
- 达到任务触发条件,调度中心下发任务
- 执行器基于线程池执行任务,并把执行结果放入内存队列中、把执行日志写入日志文件中
- 执行器消费内存队列中的执行结果,主动上报给调度中心
- 当用户在调度中心查看任务日志,调度中心请求任务执行器,任务执行器读取任务日志文件并返回日志详情
5.搭建XXL-JOB —— 调度中心
5.1 下载与查看XXL-JOB
🏠 下载 XXL-JOB:
- GitHub:https://github.com/xuxueli/xxl-job
- 码云:https://gitee.com/xuxueli0323/xxl-job
我们这里使用2.3.1版本: https://github.com/xuxueli/xxl-job/releases/tag/2.3.1
使用IDEA打开解压后的目录:

xxl-job-admin:调度中心xxl-job-core:公共依赖xxl-job-executor-samples:执行器Sample示例(选择合适的版本执行器,可直接使用)- xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器,推荐这种方式;
- xxl-job-executor-sample-frameless:无框架版本;
doc:文档资料,包含数据库脚本
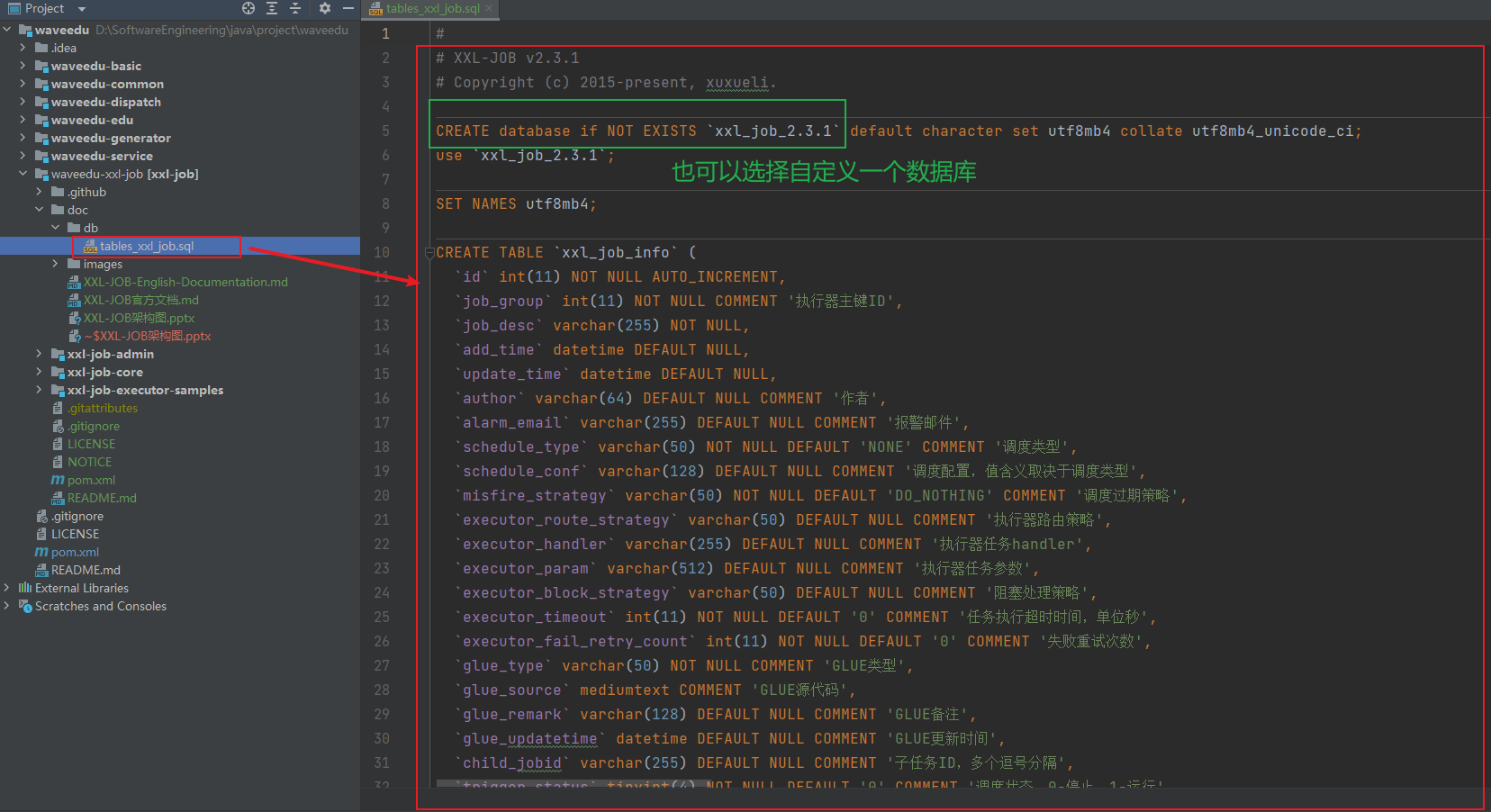
5.2 创建数据库表
打开脚本,全选执行即可。
⚠️ 注意事项:
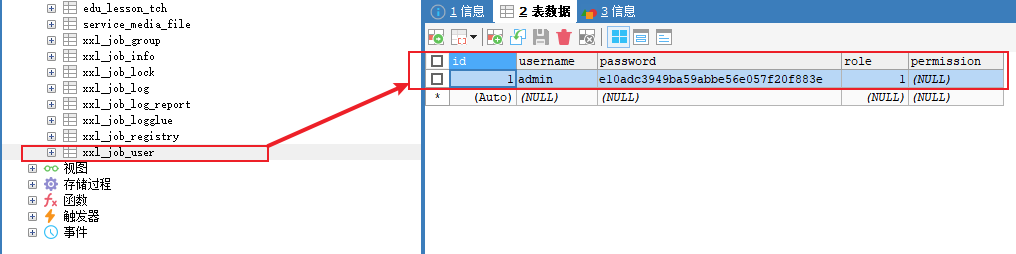
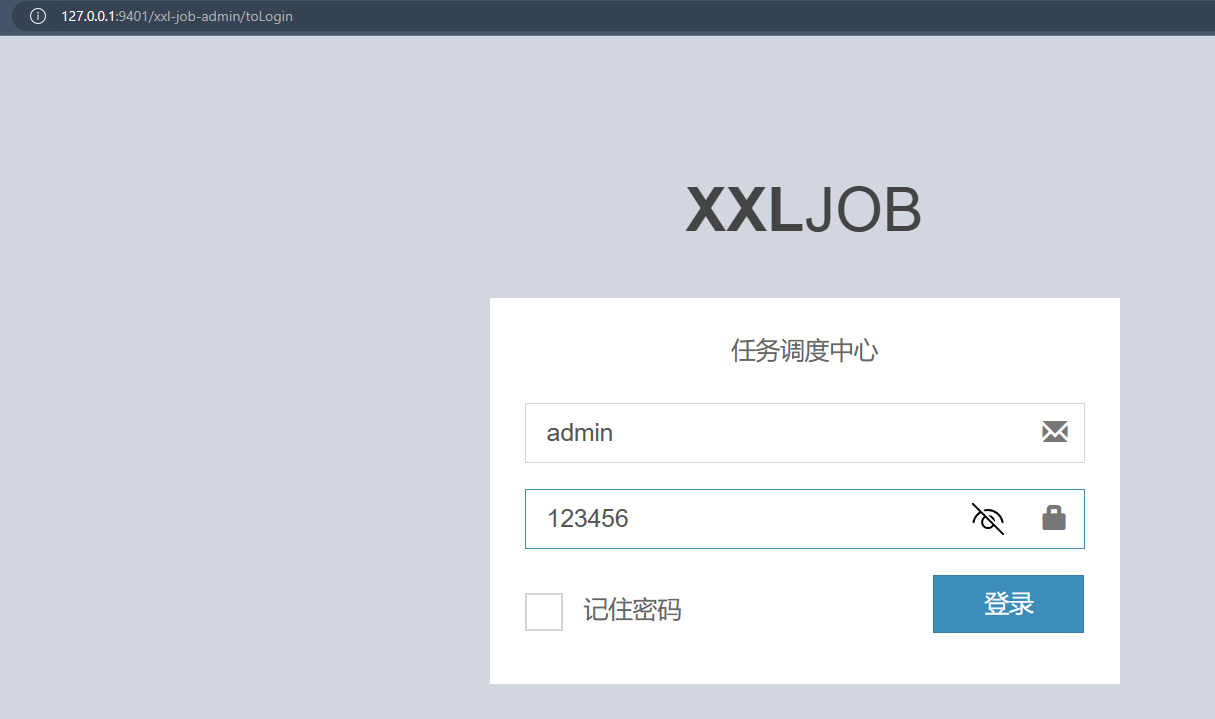
之后我们在访问调度中心时,需要登录用户名和密码,默认为:
- 用户名:admin
- 密码:123456
这个信息在数据库的 xxl_job_user 进行保存和登录验证:
5.3 修改默认的配置信息
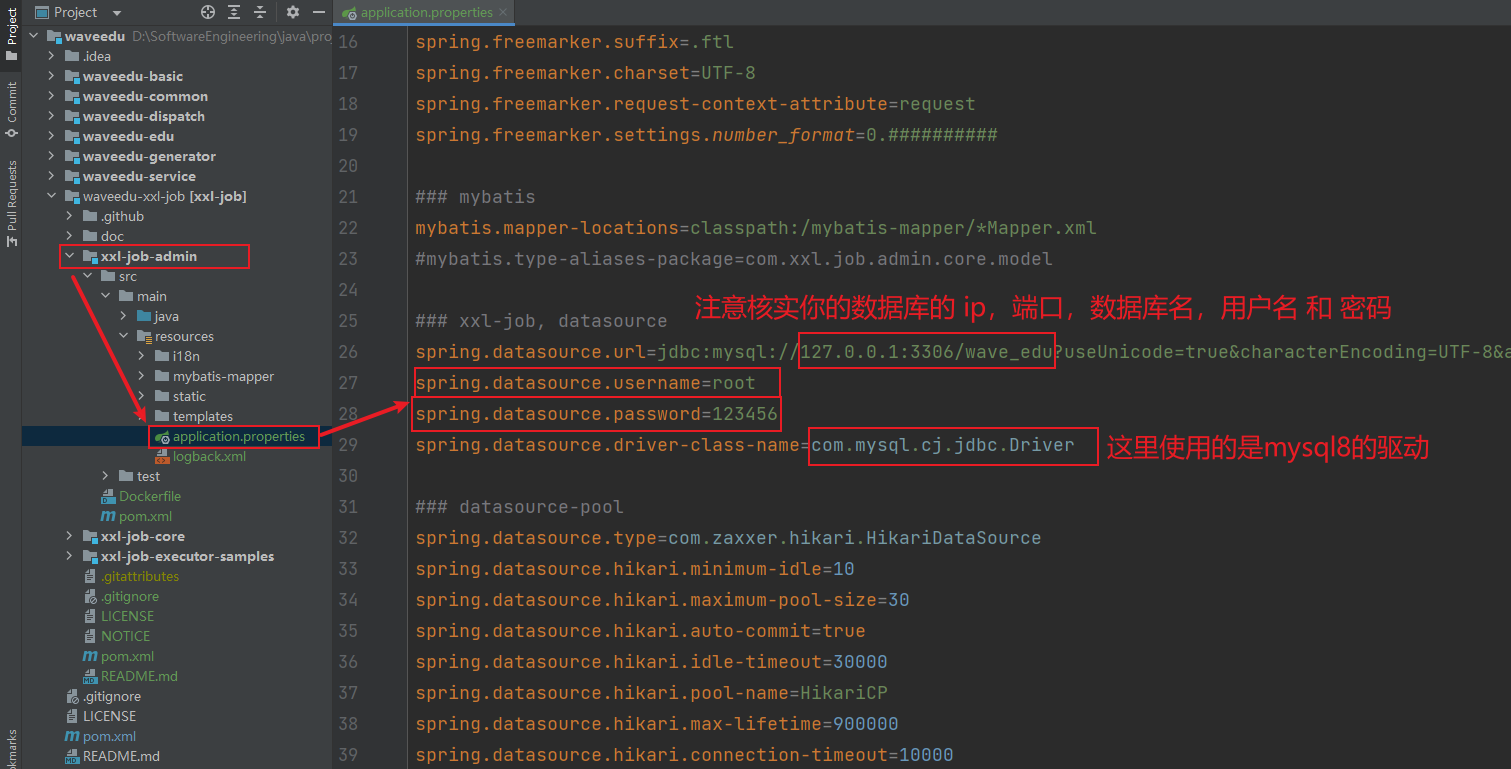
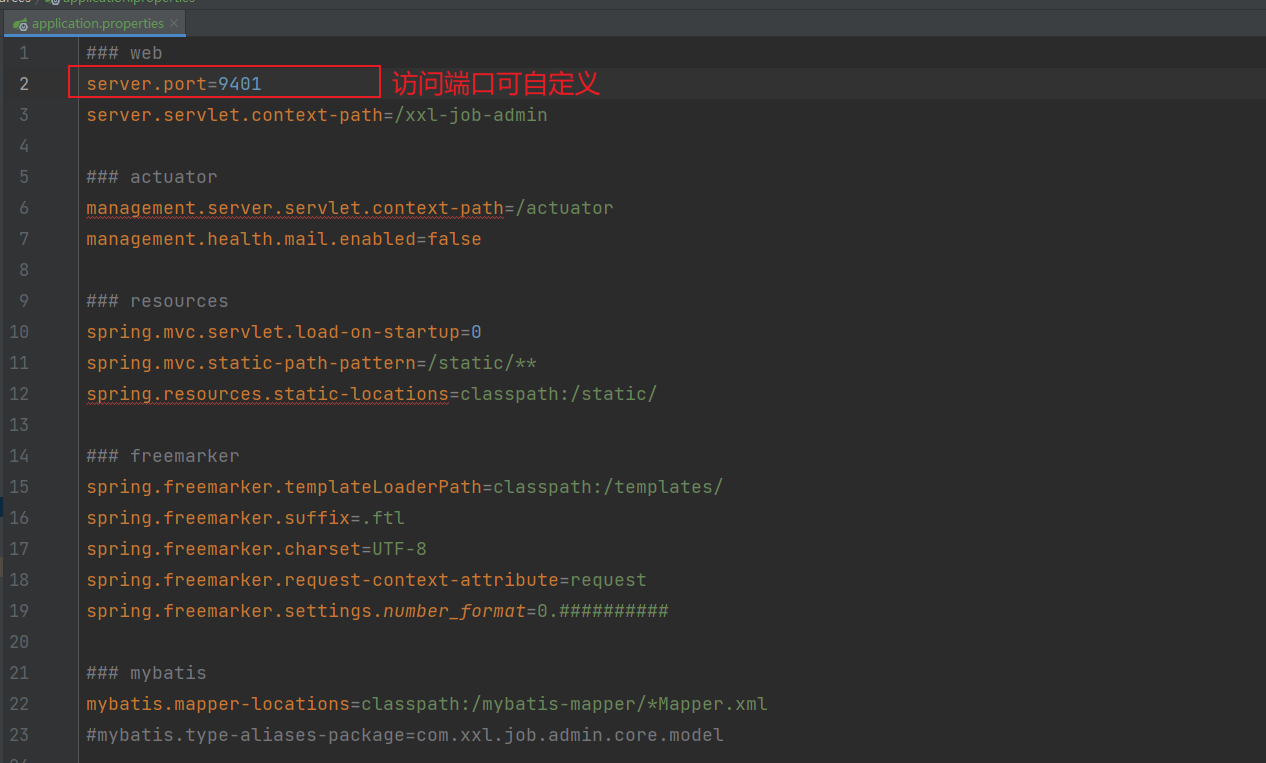
5.4 启动服务程序
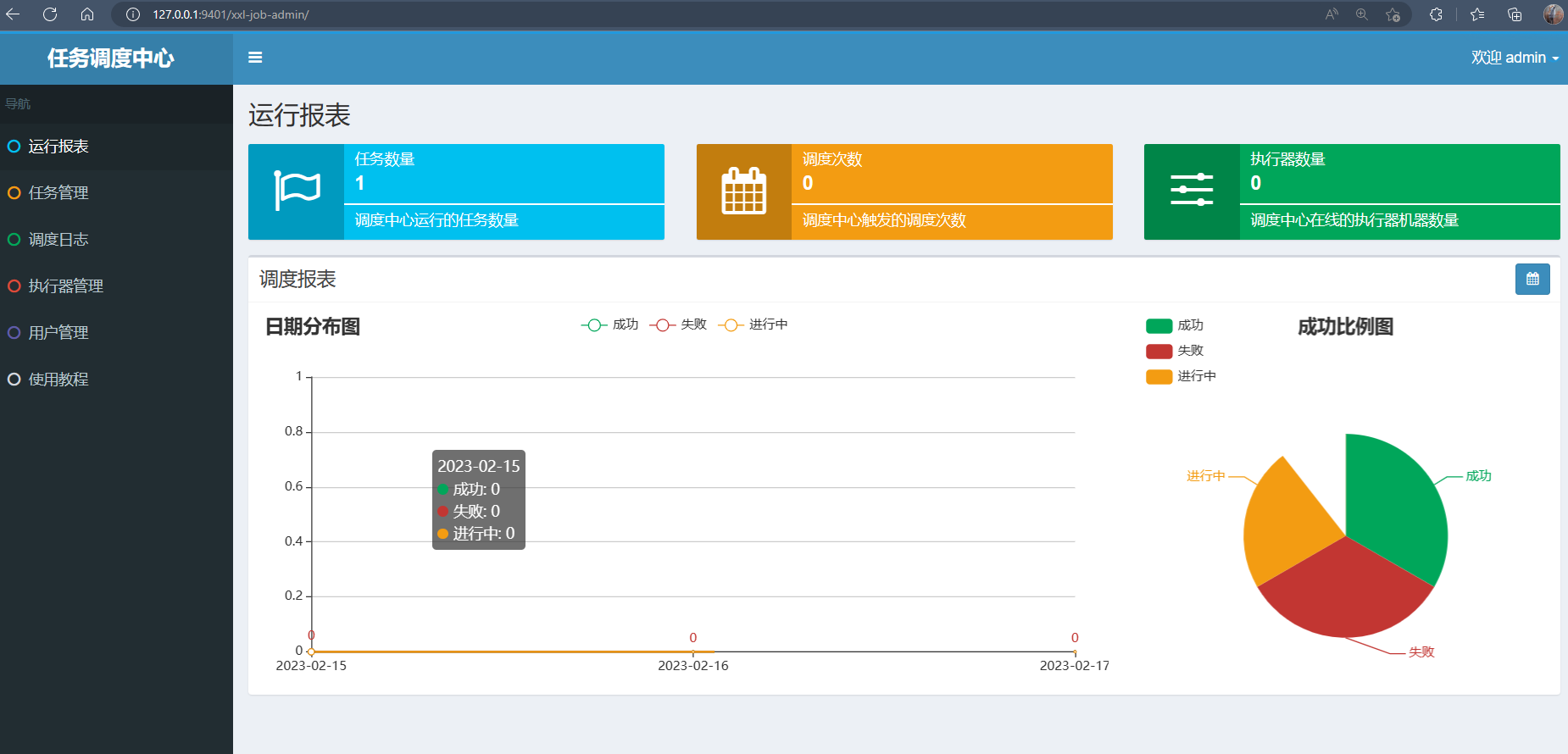
5.5 访问调度中心控制台
🏠 http://127.0.0.1:9401/xxl-job-admin/
6.搭建XXL-JOB —— 执行器
下边配置执行器,执行器负责与调度中心通信接收调度中心发起的任务调度请求。
这里为了方便演示,我们创一个新的空maven项目充当执行器进行演示:
6.1 pom.xml核心配置
<dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId><version>2.3.1</version>
</dependency>
6.2 application.yaml核心配置
server:# 指定服务端口port: 10001
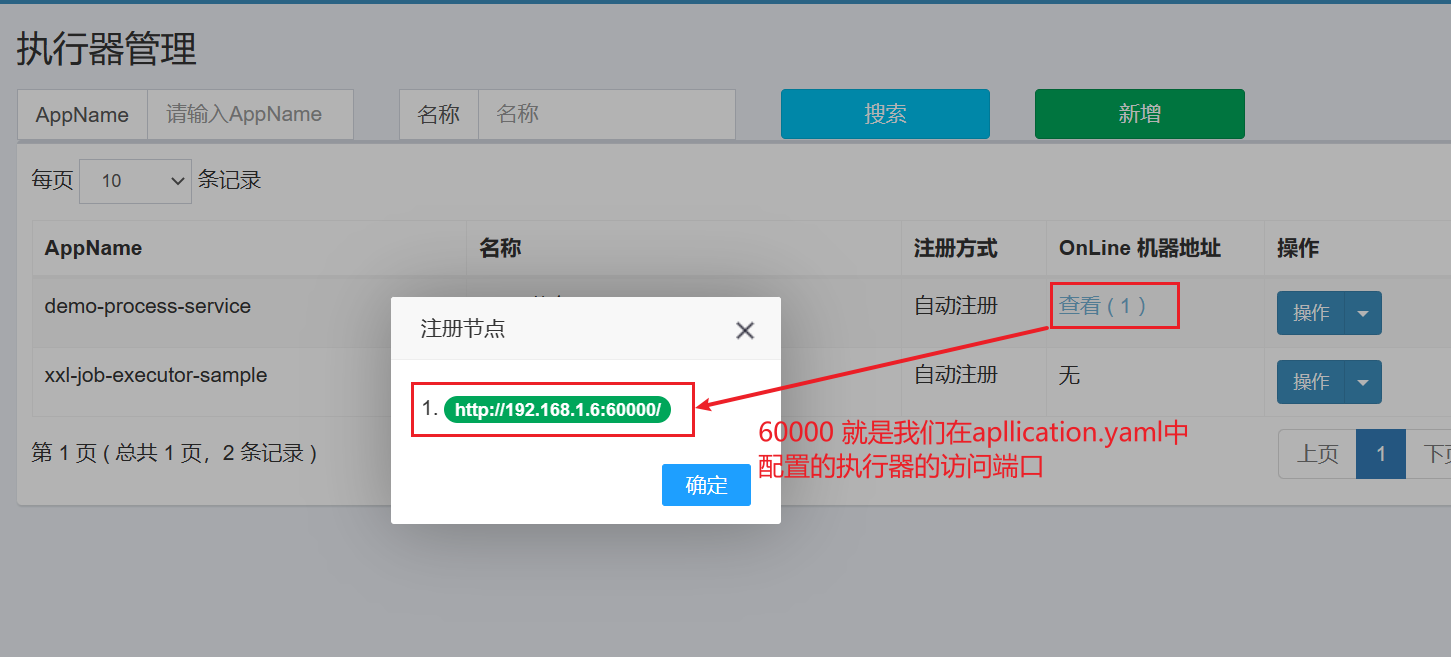
xxl:job:admin:# 调度中心的部署地址。若调度中心采用集群部署,存在多个地址,则用逗号分隔。执行器将会使用该地址进行”执行器心跳注册”和”任务结果回调”。addresses: http://localhost:9401/xxl-job-adminexecutor:# 执行器的应用名称,它是执行器心跳注册的分组依据。appname: demo-process-serviceaddress:# 执行器的IP地址,用于”调度中心请求并触发任务”和”执行器注册”。执行器IP默认为空,表示自动获取IP。多网卡时可手动设置指定IP,手动设置IP时将会绑定Host。ip:# 执行器的端口号,默认值为9999。单机部署多个执行器时,注意要配置不同的执行器端口。调度中心需要从执行器拉取日志,指定调度中心访问本执行器的端口。port: 60000# 执行器输出的日志文件的存储路径,需要拥有该路径的读写权限。logpath: /data/applogs/xxl-job/jobhandler# 执行器日志文件的定期清理功能,指定日志保存天数,日志文件过期自动删除。限制至少保存3天,否则功能不生效。这里指定为30天。logretentiondays: 30# 执行器的通信令牌,非空时启用。accessToken: default_token
注意配置中的appname这是执行器的应用名,稍后在调度中心配置执行器时要使用。
6.3 XxlJobConfig配置类
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** xxl-job config** @author xuxueli 2017-04-28*/
@Configuration
public class XxlJobConfig {private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);@Value("${xxl.job.admin.addresses}")private String adminAddresses;@Value("${xxl.job.accessToken}")private String accessToken;@Value("${xxl.job.executor.appname}")private String appname;@Value("${xxl.job.executor.address}")private String address;@Value("${xxl.job.executor.ip}")private String ip;@Value("${xxl.job.executor.port}")private int port;@Value("${xxl.job.executor.logpath}")private String logPath;@Value("${xxl.job.executor.logretentiondays}")private int logRetentionDays;@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {logger.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;}/*** 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;** 1、引入依赖:* <dependency>* <groupId>org.springframework.cloud</groupId>* <artifactId>spring-cloud-commons</artifactId>* <version>${version}</version>* </dependency>** 2、配置文件,或者容器启动变量* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'** 3、获取IP* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();*/}
6.4 XxlJobDemoApplication启动类
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;/*** @author 狐狸半面添* @create 2023-02-17 17:19*/
@SpringBootApplication
public class XxlJobDemoApplication {public static void main(String[] args) {SpringApplication.run(XxlJobDemoApplication.class);}
}
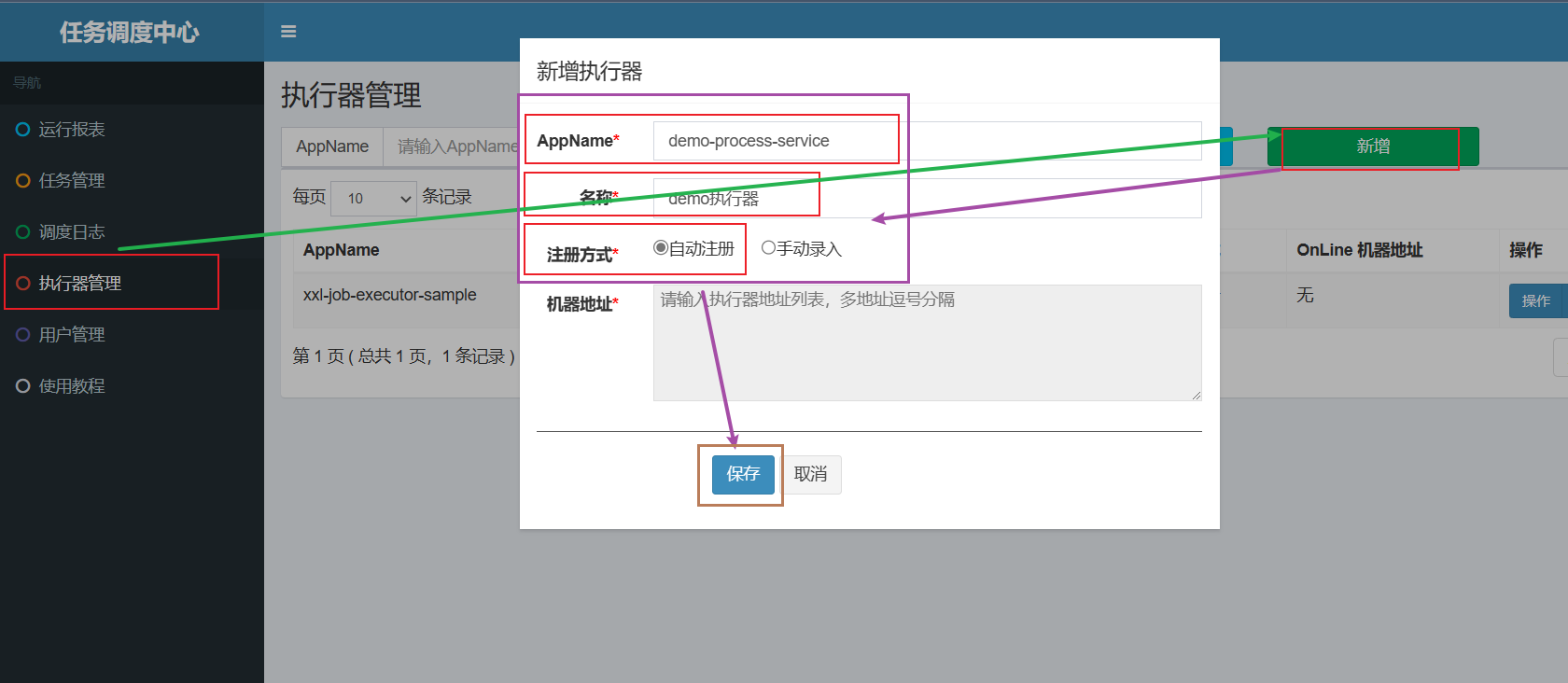
6.5 进入调度中心添加执行器
先启动调度中心服务和执行器服务。
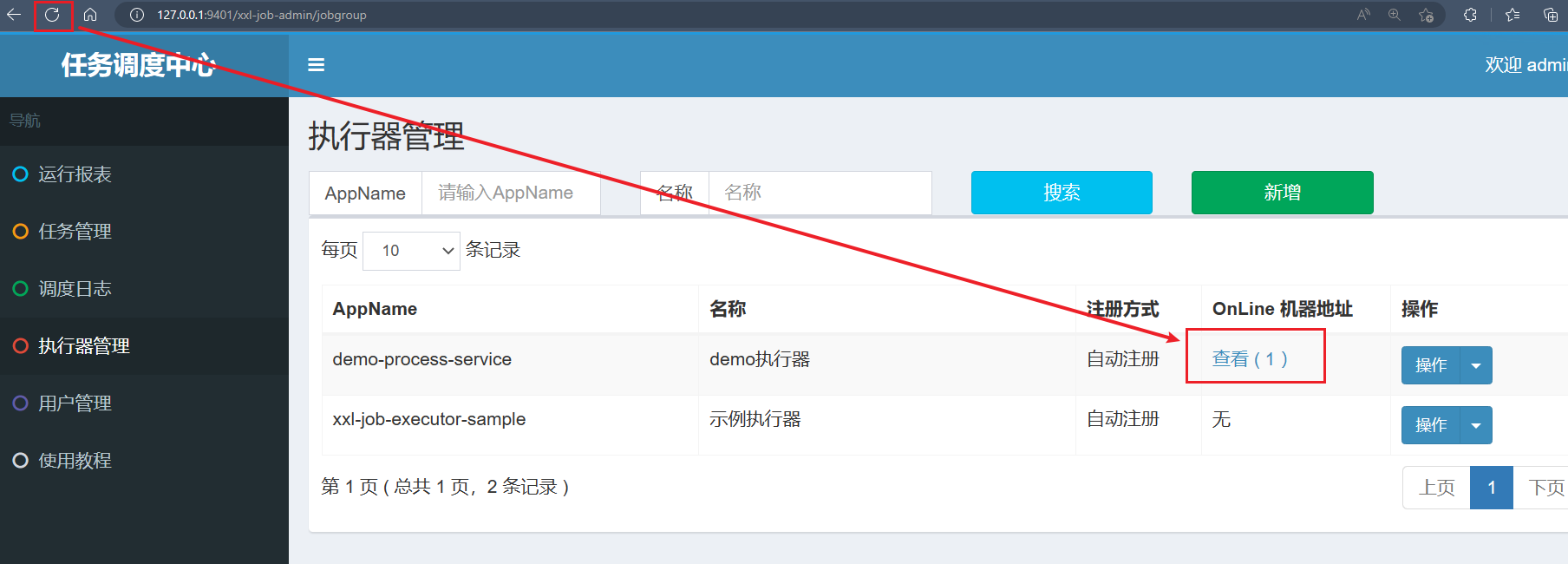
AppName:需要从application.yaml中拿到名称:可以自定义注册方式:选择 自动注册
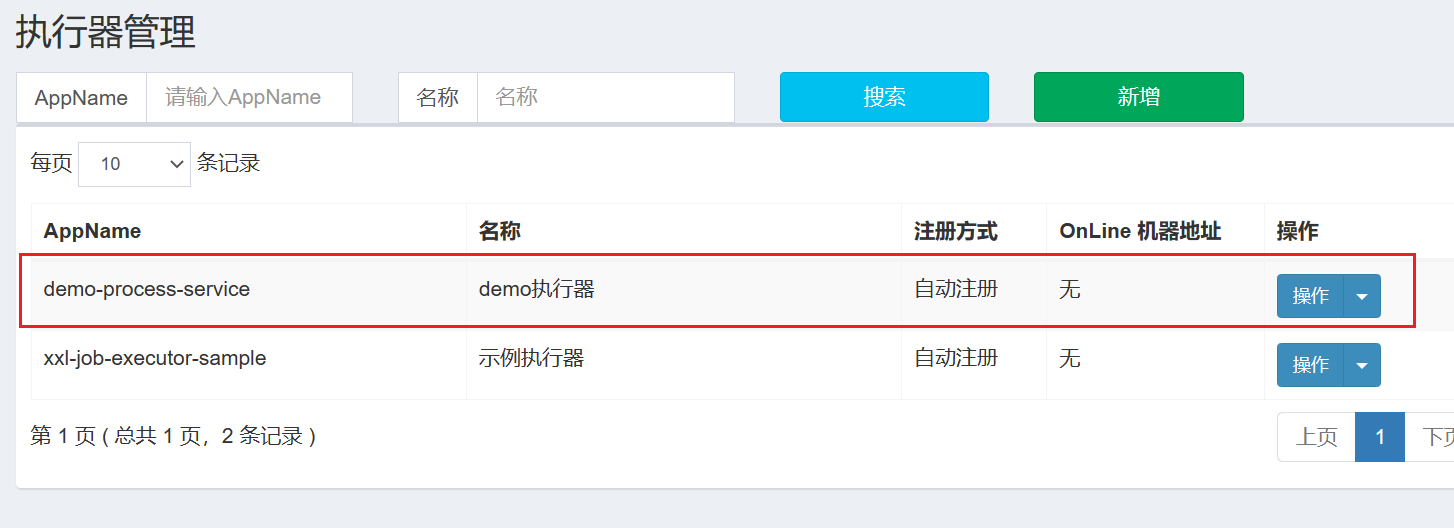
我们需要再刷新一下页面,就可以看到在线的执行器的机器地址:
7.搭建XXL-JOB —— 执行任务
先编写一个任务类:
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;import java.util.concurrent.TimeUnit;/*** XxlJob开发示例(Bean模式)* 开发步骤:* 1、任务开发:在Spring Bean实例中,开发Job方法;* 2、注解配置:为Job方法添加注解 "@XxlJob(value="自定义jobhandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")",注解value值对应的是调度中心新建任务的JobHandler属性的值。* 3、执行日志:需要通过 "XxlJobHelper.log" 打印执行日志;* 4、任务结果:默认任务结果为 "成功" 状态,不需要主动设置;如有诉求,比如设置任务结果为失败,可以通过 "XxlJobHelper.handleFail/handleSuccess" 自主设置任务结果;** @author 狐狸半面添* @create 2023-02-17 17:41*/
@Component
public class XxlJobDemo {}
7.1 简单任务示例(Bean模式)
7.1.1 编写任务方法
package com.xxl.demo.component;import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;import java.util.concurrent.TimeUnit;/*** XxlJob开发示例(Bean模式)* 开发步骤:* 1、任务开发:在Spring Bean实例中,开发Job方法;* 2、注解配置:为Job方法添加注解 "@XxlJob(value="自定义jobhandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")",注解value值对应的是调度中心新建任务的JobHandler属性的值。* 3、执行日志:需要通过 "XxlJobHelper.log" 打印执行日志;* 4、任务结果:默认任务结果为 "成功" 状态,不需要主动设置;如有诉求,比如设置任务结果为失败,可以通过 "XxlJobHelper.handleFail/handleSuccess" 自主设置任务结果;** @author 狐狸半面添* @create 2023-02-17 17:41*/
@Component
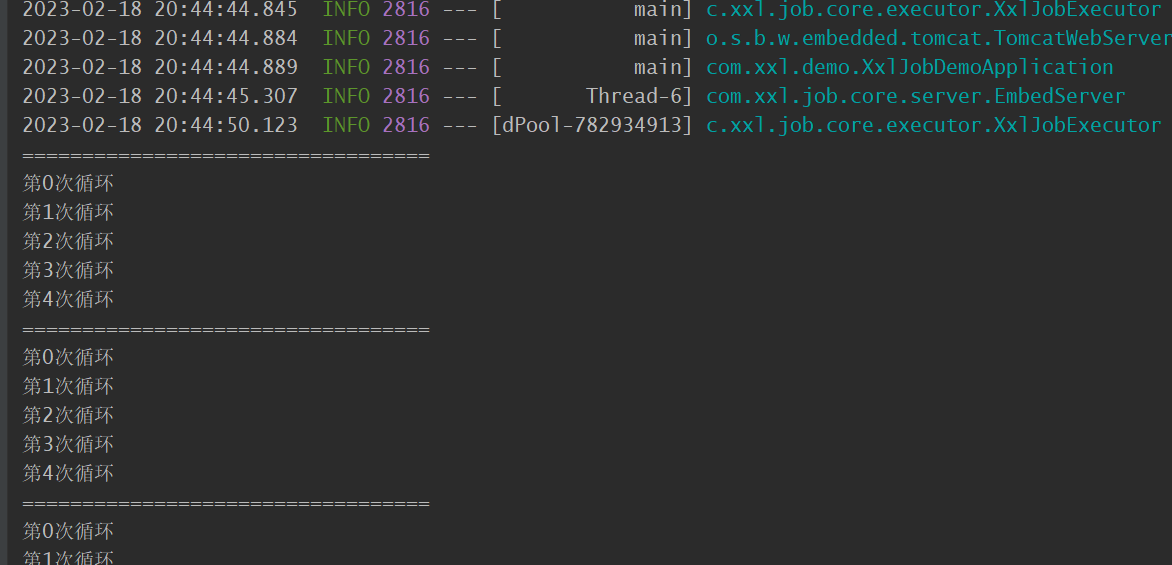
public class XxlJobDemo {/*** 简单任务示例(Bean模式)*/@XxlJob("demoJobHandler")public void demoJobHandler() throws Exception {// 打印日志XxlJobHelper.log("简单任务示例方法执行");System.out.println("==================================");for (int i = 0; i < 5; i++) {System.out.println("第" + i + "次循环");TimeUnit.MILLISECONDS.sleep(500);}// default success}
}
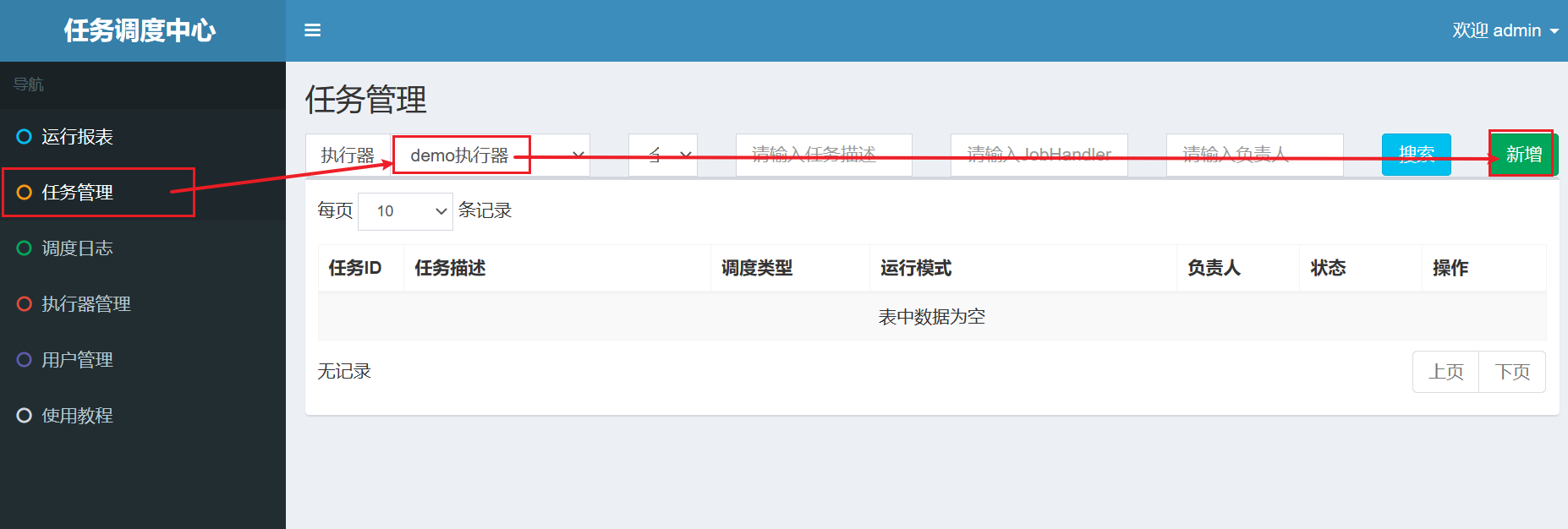
7.1.2 在调度中心进行任务管理
记得先将服务重启。
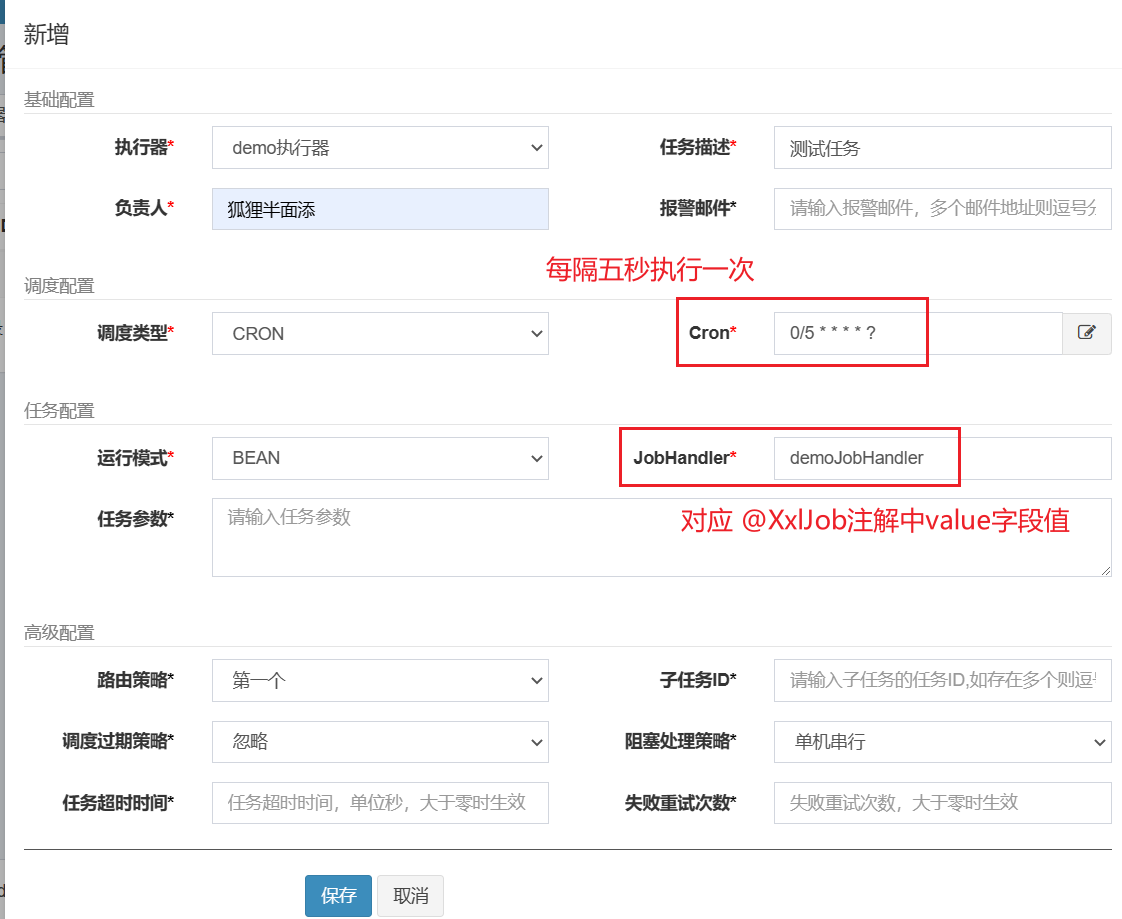
调度类型选择Cron,并配置Cron表达式设置定时策略。Cron表达式是一个字符串,通过它可以定义调度策略,格式如下:
{秒数} {分钟} {小时} {日期} {月份} {星期} {年份(可为空)}
xxl-job提供图形界面去配置:
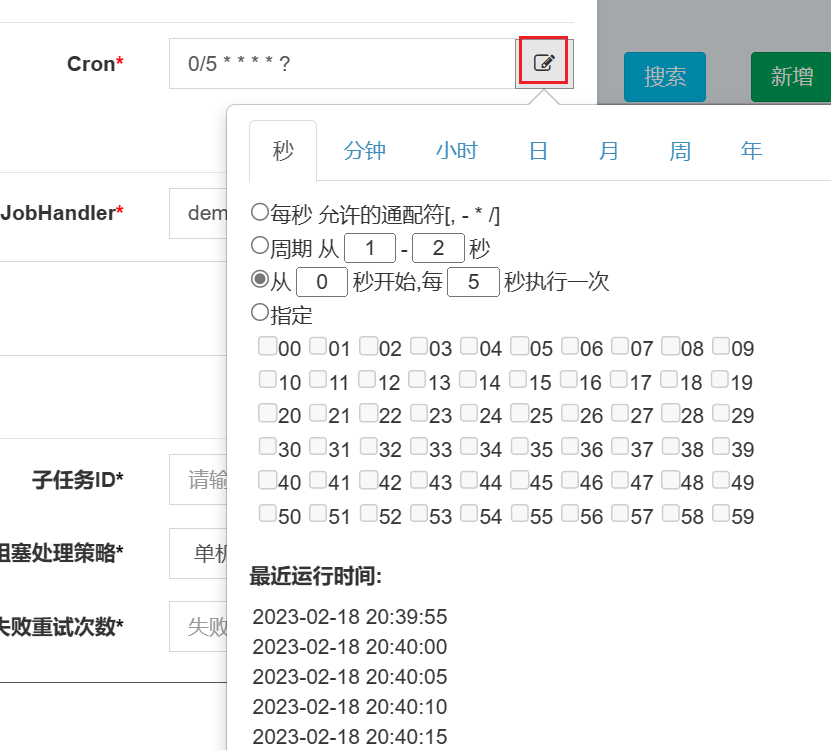
📝 一些例子如下:
- 30 10 1 * * ? 每天1点10分30秒触发
- 0/30 * * * * ? 每30秒触发一次
- 0 0/10 * * * ? 每10分钟触发一次
运行模式有BEAN和GLUE,bean模式较常用就是在项目工程中编写执行器的任务代码,GLUE是将任务代码编写在调度中心。
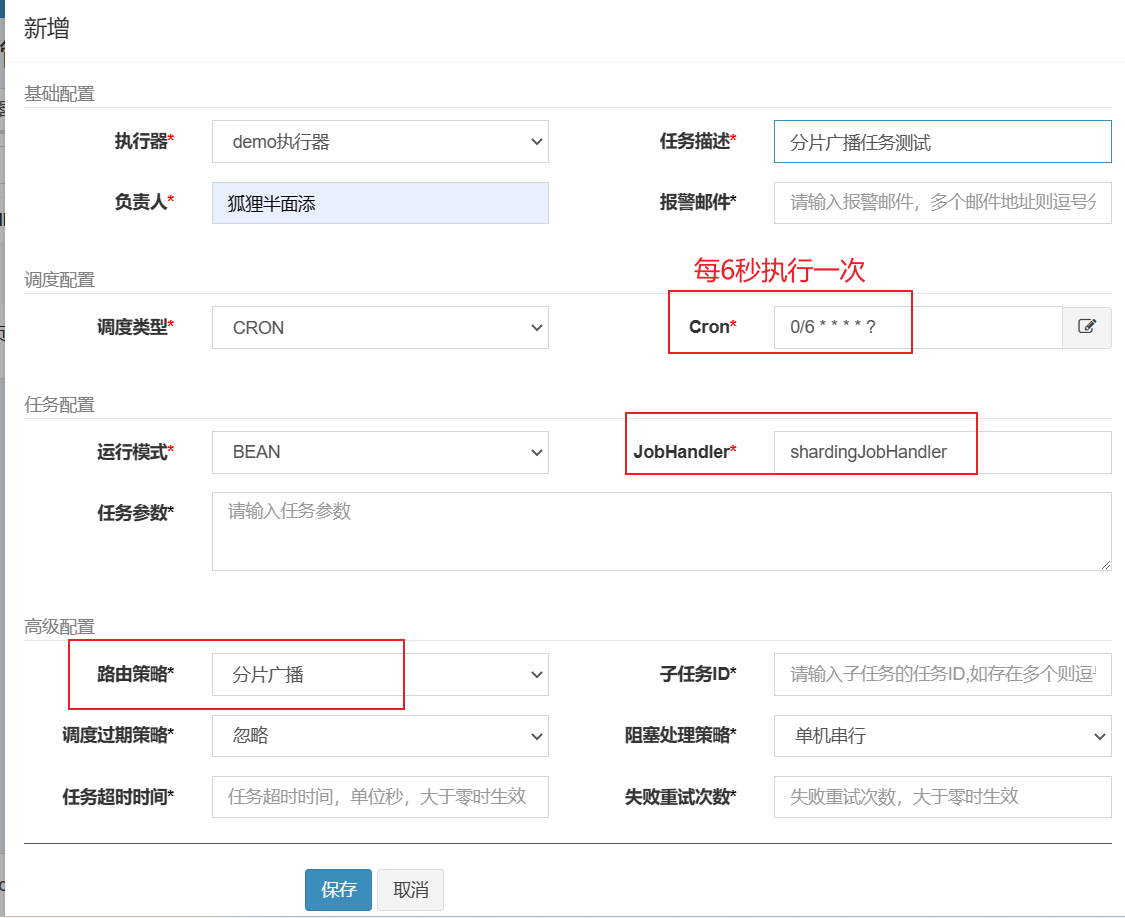
JobHandler任务方法名填写@XxlJob注解中的名称。
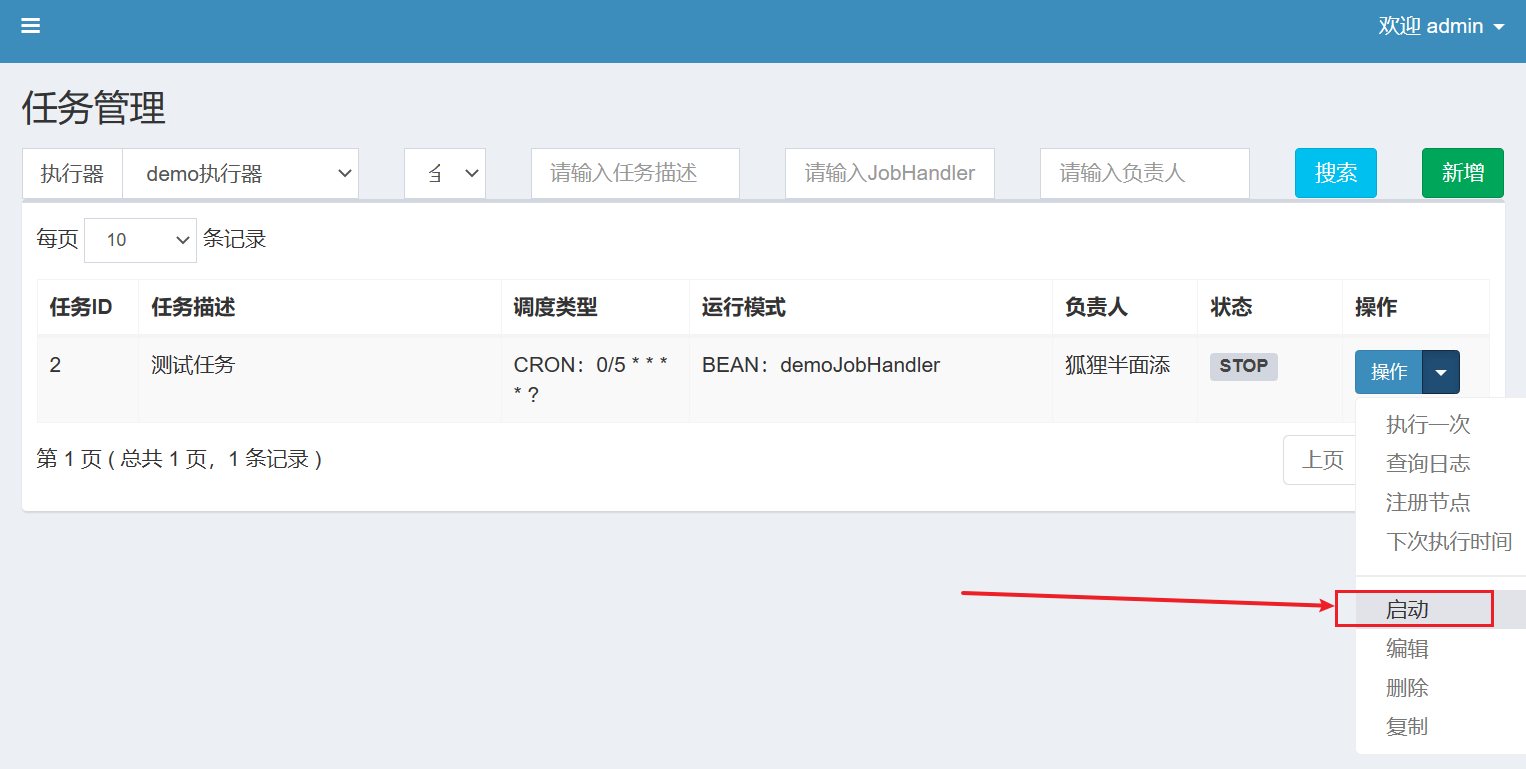
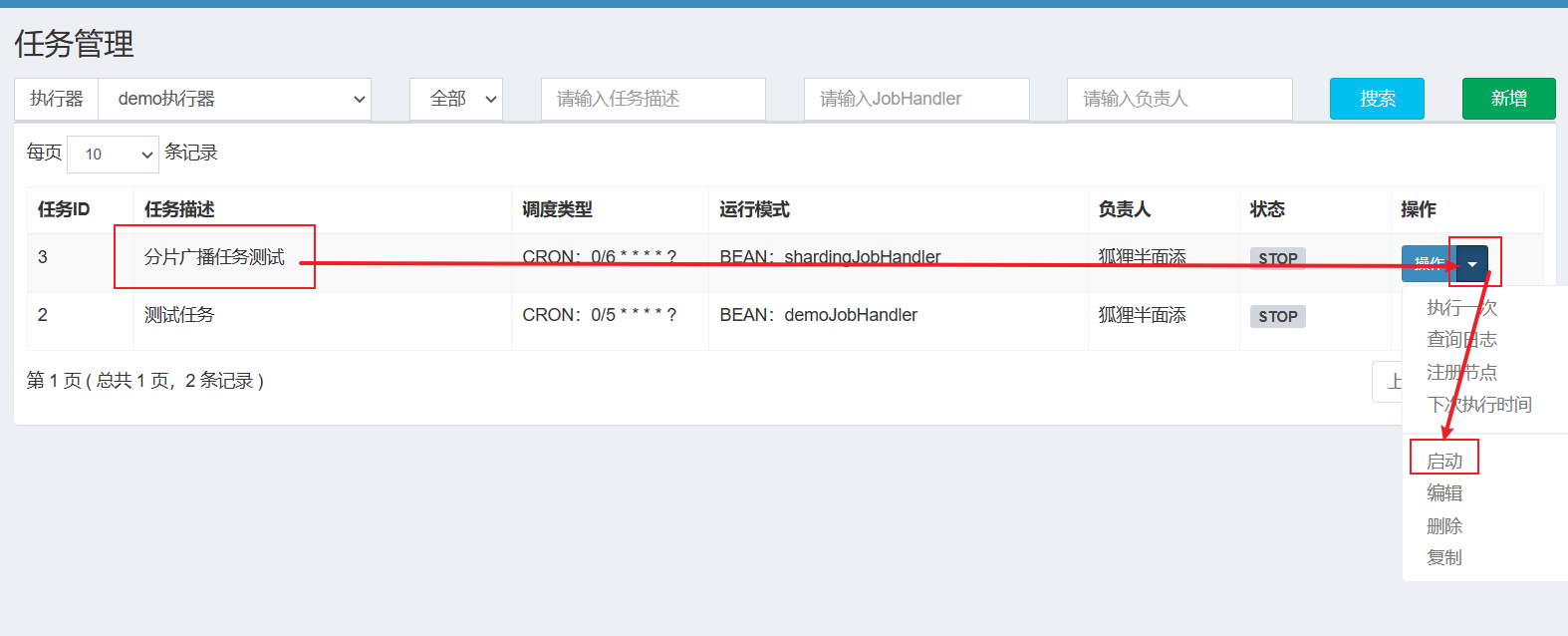
新增成功,就启动任务:
查看Java控制台:
查看日志:
任务跑一段时间注意清理日志:
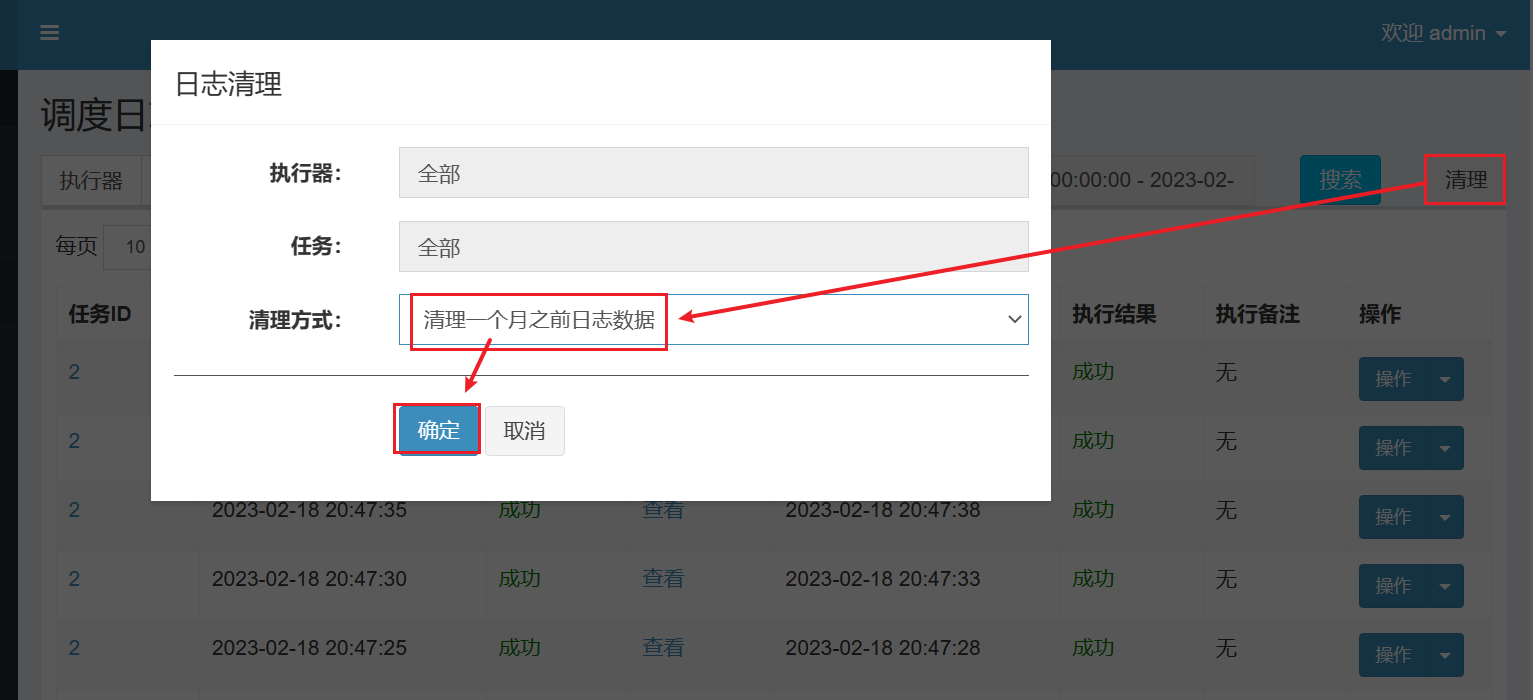
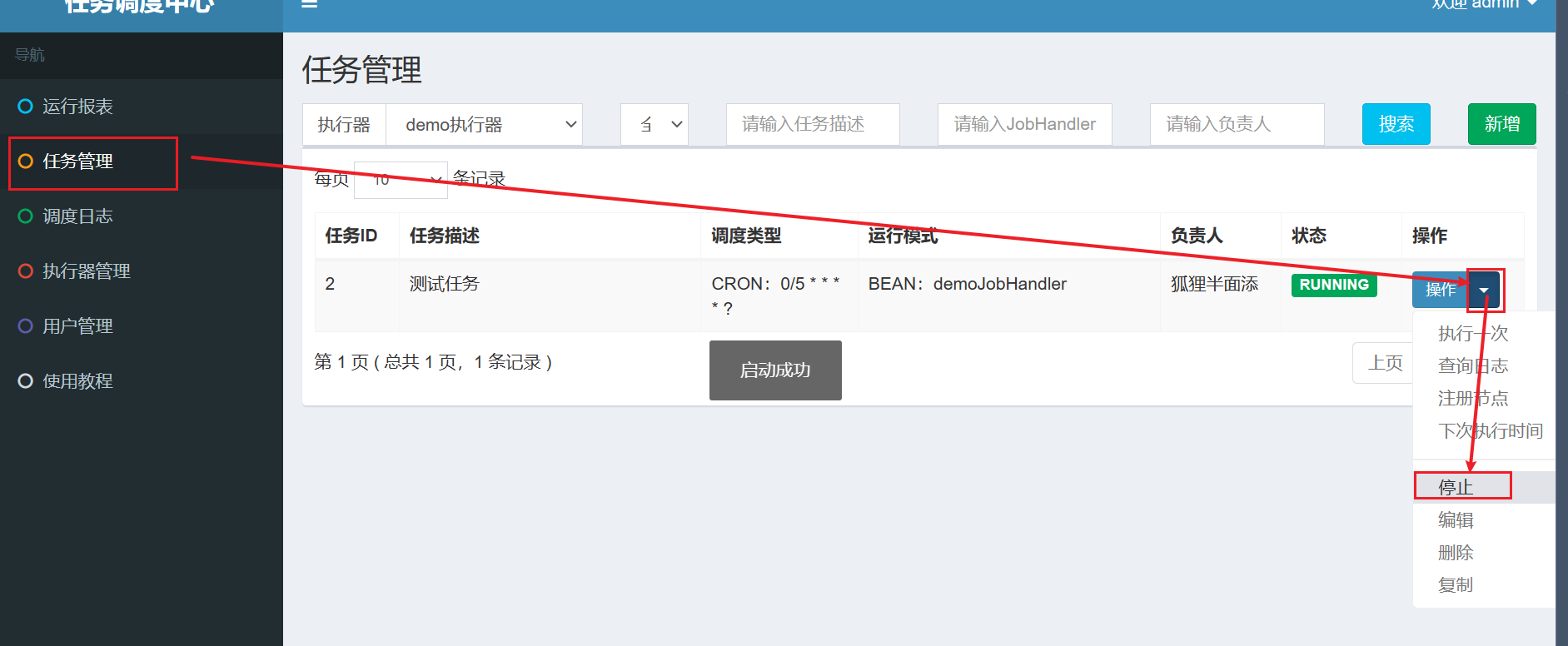
如果要停止任务需要在调度中心操作:
7.2 调度策略
执行器在集群部署下调度中心有哪些调度策略呢?查看xxl-job官方文档,阅读高级配置相关的内容:
路由策略:当执行器集群部署时,提供丰富的路由策略,包括:
FIRST(第一个):每次调度选择集群中第一台执行器。LAST(最后一个):每次调度选择集群中最后一台执行器。ROUND(轮询):按照顺序每次调度选择一台执行器去调度。RANDOM(随机):每次调度随机选择一台执行器去调度。CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举。LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举。FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度。BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度。SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务。
7.3 分片广播
我们思考一下如何进行分布式任务处理呢?如下图,我们会启动多个执行器组成一个集群,去执行任务。
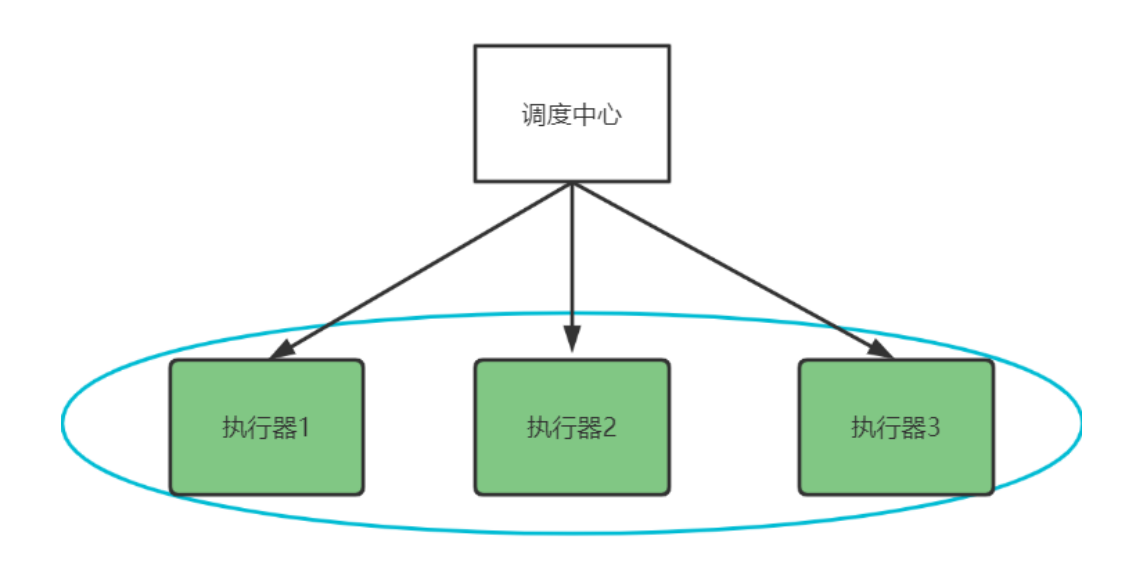
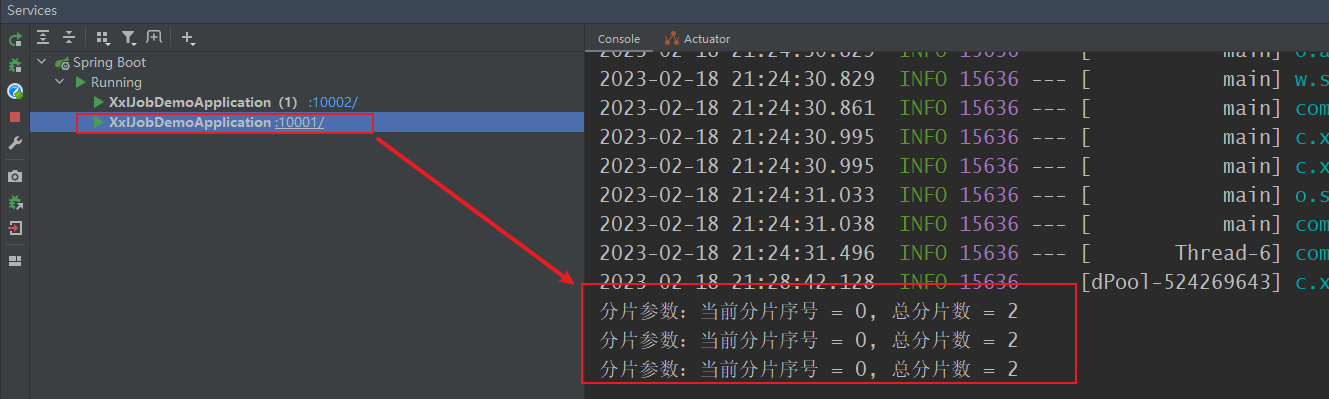
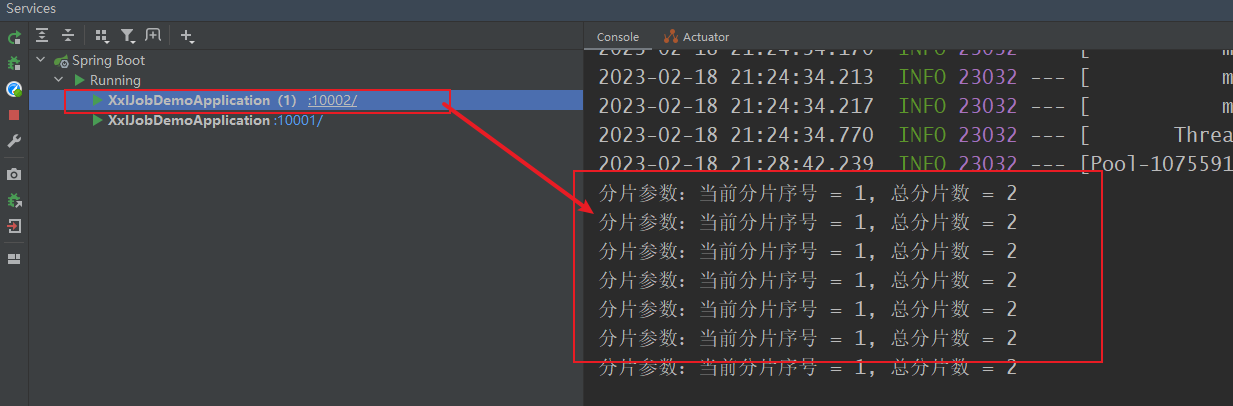
分片广播策略:分片是指是调度中心将集群中的执行器标上序号:0,1,2,3…,广播是指每次调度会向集群中所有执行器发送调度请求,请求中携带分片参数。
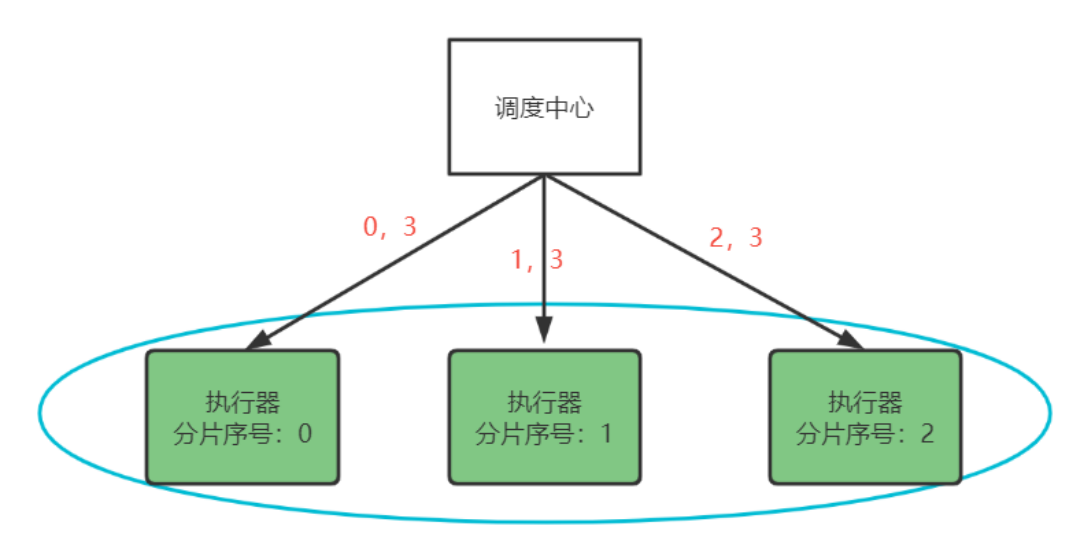
每个执行器收到调度请求根据分片参数自行决定是否执行任务。
另外xxl-job还支持动态分片,当执行器数量有变更时,调度中心会动态修改分片的数量。
📍 作业分片适用哪些场景呢?
分片任务场景:10个执行器的集群来处理10w条数据,每台机器只需要处理1w条数据,耗时降低10倍;广播任务场景:广播执行器同时运行shell脚本、广播集群节点进行缓存更新等。
所以,广播分片方式不仅可以充分发挥每个执行器的能力,并且根据分片参数可以控制任务是否执行,最终灵活控制了执行器集群分布式处理任务。
💬 “分片广播” 和普通任务开发流程一致,不同之处在于可以获取分片参数进行分片业务处理。
7.3.1 编写任务方法
/*** 分片广播任务*/@XxlJob("shardingJobHandler")public void shardingJobHandler() throws Exception {/*分片参数:- shardIndex:分片序号- shardTotal:分片总数*/int shardIndex = XxlJobHelper.getShardIndex();int shardTotal = XxlJobHelper.getShardTotal();System.out.printf("分片参数:当前分片序号 = %d, 总分片数 = %d\n", shardIndex, shardTotal);XxlJobHelper.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);// todo 业务逻辑}
7.3.2 增加一个节点服务
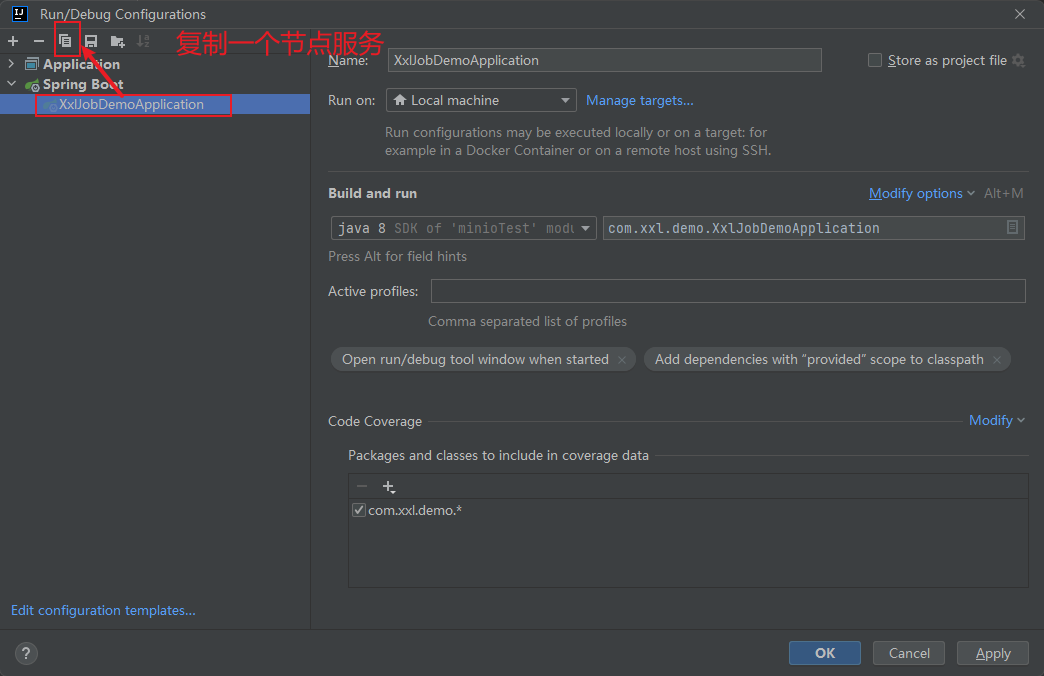
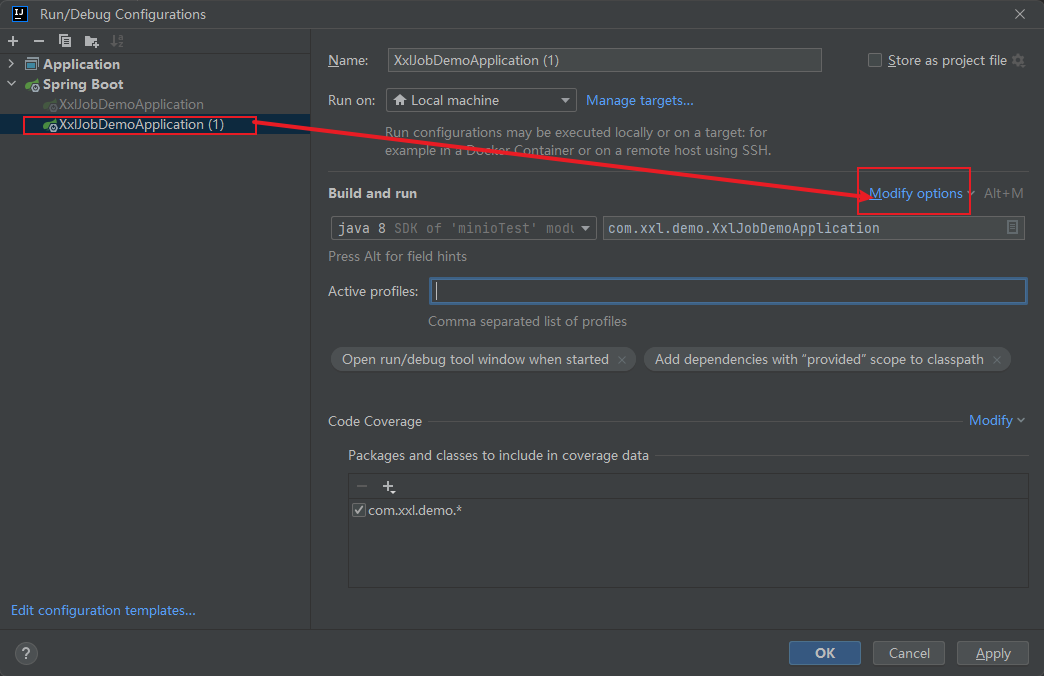
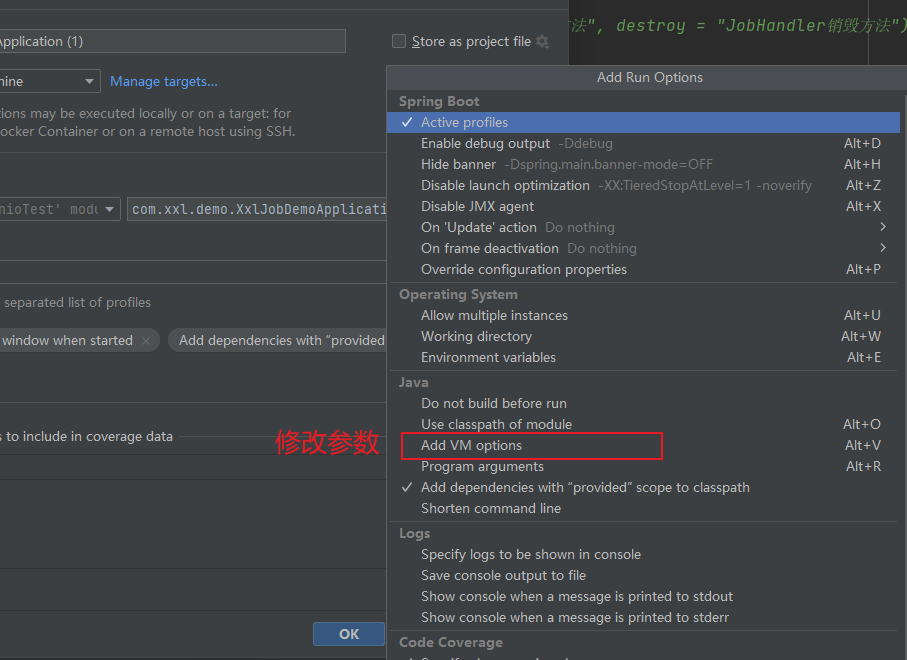
修改新节点的服务端口和执行器访问端口信息:-Dserver.port=10002 -Dxxl.job.executor.port=60001
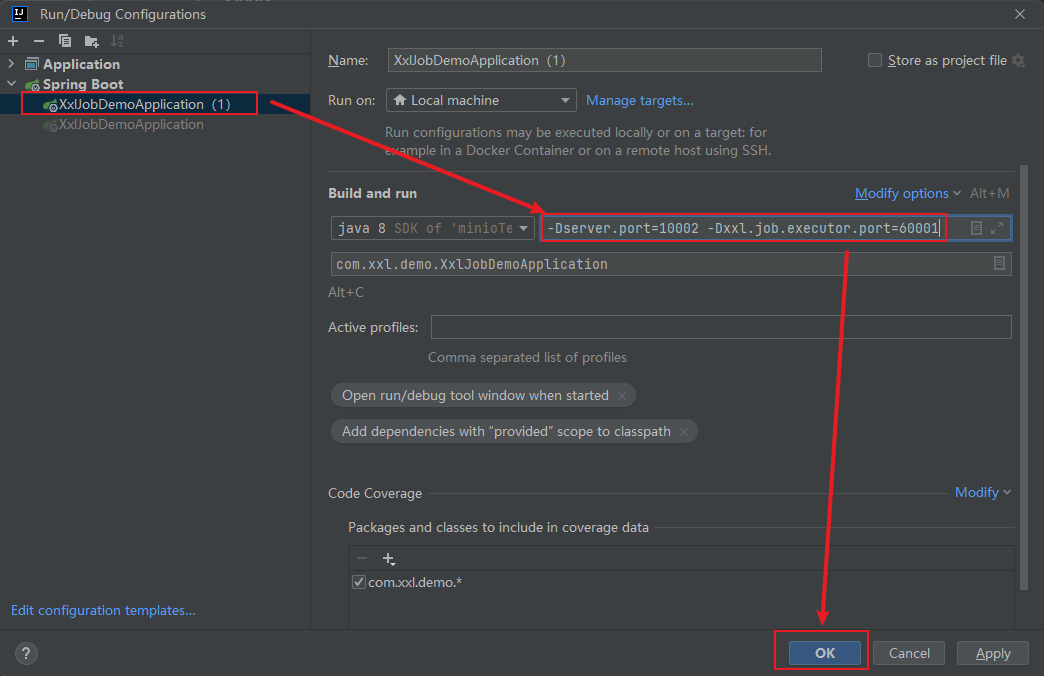
启动这两个服务:
7.3.3 调度中心-执行器管理
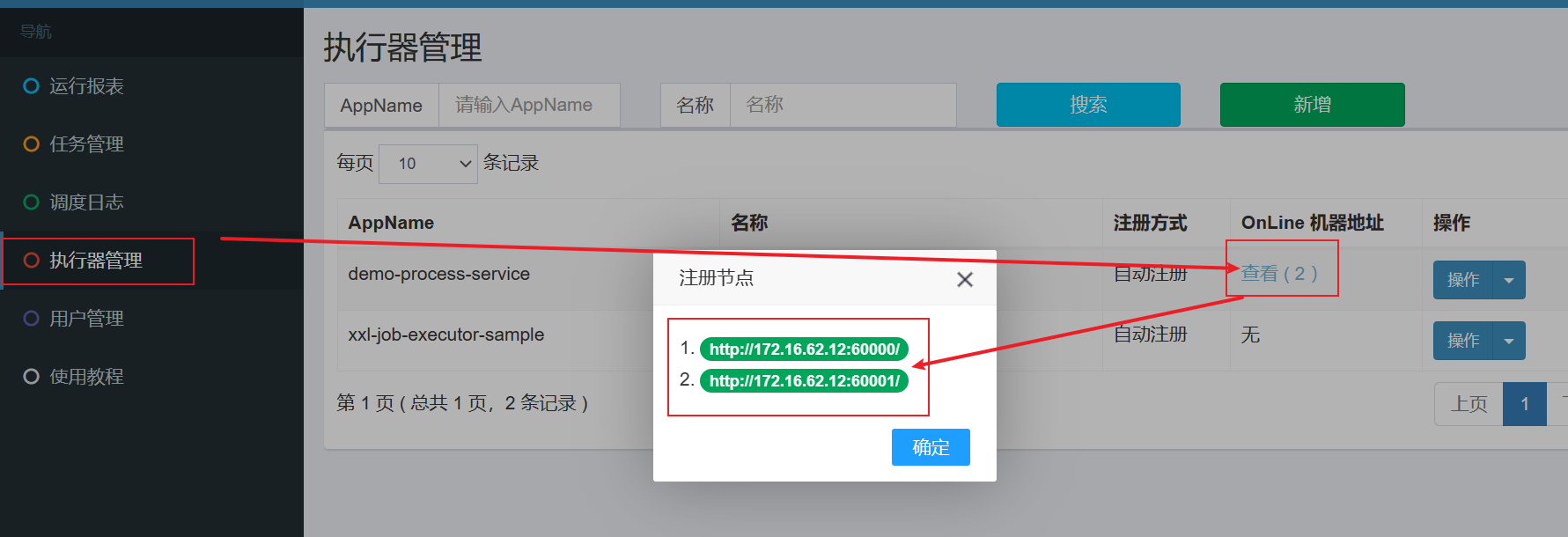
上图说明在调度中心已经注册成功。
7.3.4 调度中心-新增与启用任务
7.3.5 校验任务
7.4 高级配置说明
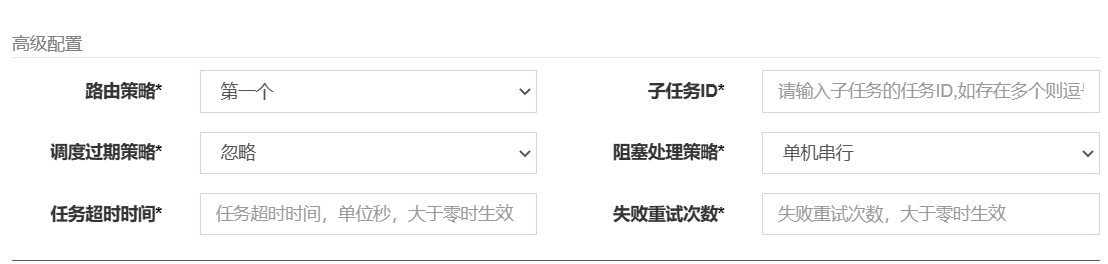
7.4.1 子任务
每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度,通过子任务可以实现一个任务执行完成去执行另一个任务。
7.4.2 调度过期策略
忽略:调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间。立即执行一次:调度过期后,立即执行一次,并从当前时间开始重新计算下次触发时间。
7.4.3 阻塞处理策略
调度过于密集执行器来不及处理时的处理策略
单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行。丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败。覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务。
7.4.4 任务超时时间
支持自定义任务超时时间,任务运行超时将会主动中断任务。
7.4.5 失败重试次数
支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试。
8.作业分片方案
❓ 当一次分片广播到来,各执行器如何根据分片参数去分布式执行任务,保证执行器之间执行的任务不重复呢?
执行器收到调度请求后各自己查询属于自己的任务,这样就保证了执行器之间不会重复执行任务。
xxl-job设计作业分片就是为了分布式执行任务,XXL-JOB并不直接提供数据处理的功能,它只会给执行器分配好分片序号并向执行器传递分片总数、分片序号这些参数,开发者需要自行处理分片项与真实数据的对应关系。
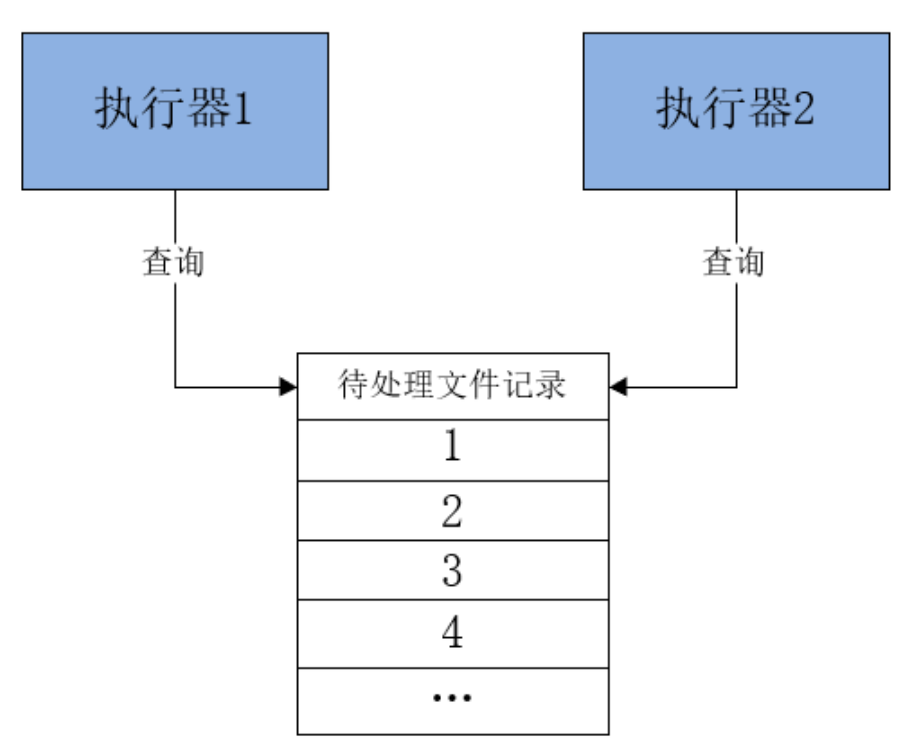
每个执行器收到广播任务有两个参数:分片总数、分片序号。每个执行从数据表取任务时可以让任务id 模上 分片总数,如果等于分片序号则执行此任务。
上边两个执行器实例那么分片总数为2,序号为0、1,从任务1开始,如下:
- 1 % 2 = 1 执行器2执行
- 2 % 2 = 0 执行器1执行
- 3 % 2 = 1 执行器2执行
- 以此类推
9.三个经典面试题
9.1 xxl-jobo是怎么工作的?
XXL-JOB分布式任务调度服务由调用中心和执行器组成,调用中心负责按任务调度策略向执行器下发任务,执行器负责接收任务执行任务。
- 首先部署并启动xxl-job调度中心。(一个java工程)
- 首先在微服务添加xxl-job依赖,在微服务中配置执行器
- 启动微服务,执行器向调度中心上报自己.
- 在微服务中写一个任务方法并用xxl-job的注解去标记执行任务的方法名称。
- 在调度中心配置任务调度策略,调度策略就是每隔多长时间执行还是在每天或每月的固定时间去执行,比如每天0点执行,或每隔1小时执行一次等
- 在调度中心启动任务。
- 调度中心根据任务调度策略,到达时间就开始下发任务给执行器。、
- 执行器收到任务就开始执行任务。
9.2 如何保证任务不重复执行?
-
调度中心按分片广播的方式去下发任务。
-
执行器收到作业分片广播的参数:分片总数和分月序号,计算任务id除以分片总数得到一个余数,如果余数等于分片序号这时就去执行这个任务,这里保证了不同的执行器执行不同的任务。
-
配置
调度过期策略为"忽略”,避免同一个执行器多次重复执行同一个任务。忽略:调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间。
-
配置
任务阻塞处理策略为“丢弃后续调度”,注意:弃也没事下一次调度就又可以执行了。丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败。
-
另外还要保证任务处理的幂等性,执行过的任务可以打一个状态标记已完成,下次再调度执行该任务判断该任务已完成就不再执行。
9.3 如何保证任务处理的幂等性?
任务的幂等性是指:对于数据的操作不论多少次,操作的结果始终是一致的。执行器接收调度请求去执行任务,要有办法去判断该任务是否处理完成,如果处理完则不再处理,即使重复调度处理相同的任务也不能重复处理已经处理过的数据。
幂等性描述了一次和多次请求某一个资源对于资源本身应该具有同样的结果。
幂等性是为了解决重复提交问题,比如:恶意刷单,重复支付等。
📍 解决幂等性常用的方案:
-
数据库约束,比如:唯一索引,主键。
-
乐观锁,常用于数据库,更新数据时根据乐观锁状态去更新。
-
唯一序列号,请求前生成唯一的序列号,携带序列号去请求,操作时先判断与该序列号是否相等。不相等则说明已经执行过了就不再执行,否则执行并且修改序列号或删除。
例如在数据库中我们对于操作过的记录修改字段
status的值来表示已经操作。