绵阳房产网站建设企业网络推广方案
我们很高兴为您介绍RoboBrain 2.0——迄今为止最强大的开源具身智能脑模型。相比前代RoboBrain1.0,最新版本在多智能体任务规划、空间推理和闭环执行等方面取得重大突破。详细技术报告即将发布。

🚀 功能特点
RoboBrain 2.0 支持通过长远规划和闭环反馈进行交互式推理,具备从复杂指令中精确预测点坐标和边界框的空间感知能力,可实现未来轨迹预测的时间感知能力,并通过实时结构化记忆构建与更新实现场景推理。
⭐️ 架构
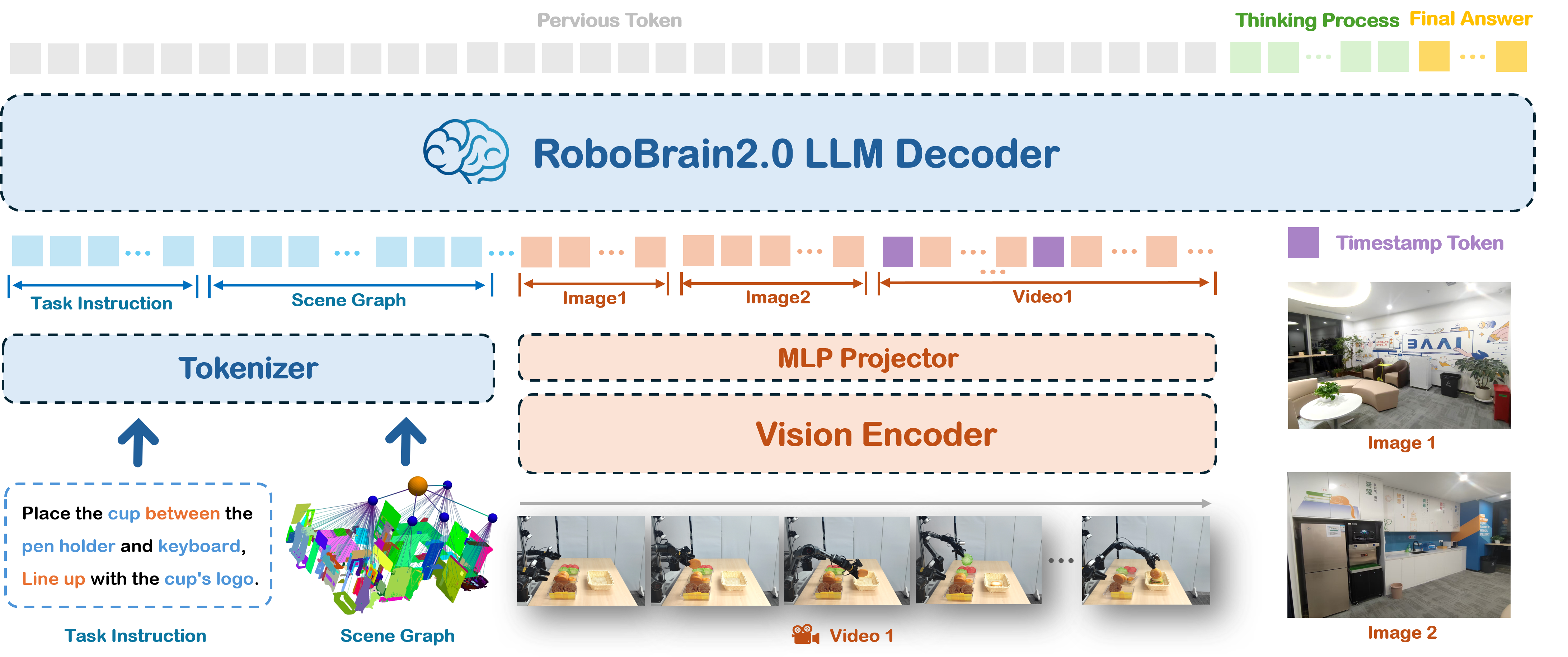
RoboBrain 2.0支持多图像、长视频和高分辨率视觉输入,同时在语言端处理复杂任务指令和结构化场景图。视觉输入通过视觉编码器和MLP投影器处理,而文本输入则被分词为统一的token流。所有输入均馈入LLM解码器,该解码器执行长链思维推理,并输出结构化规划、空间关系以及相对和绝对坐标。
https://huggingface.co/BAAI/RoboBrain2.0-7B
🛠️ 安装
# clone repo.
git clone https://github.com/FlagOpen/RoboBrain2.0.git
cd RoboBrain# build conda env.
conda create -n robobrain2 python=3.10
conda activate robobrain2
pip install -r requirements.txt
💡 简单推理
- 无思考地预测(通用)
from inference import SimpleInferencemodel = SimpleInference("BAAI/RoboBrain2.0-7B")prompt = "What is shown in this image?"
image = "http://images.cocodataset.org/val2017/000000039769.jpg"pred = model.inference(prompt, image, task="general", enable_thinking=False, do_sample=True)
print(f"Prediction:\n{pred}")"""
Prediction: (as an example)
{'thinking': '', 'answer': 'Two cats sleeping side by side on a couch.'
}
"""
Loading Checkpoint ...
##### INPUT #####
What is shown in this image?
###############
Thinking disabled.
Running inference ...
Prediction:
{'thinking': '', 'answer': 'Two cats are shown sleeping on top of a pink couch.'}
- 预测性思维(通用)
from inference import SimpleInferencemodel = SimpleInference("BAAI/RoboBrain2.0-7B")prompt = "What is shown in this image?"
image = "http://images.cocodataset.org/val2017/000000039769.jpg"pred = model.inference(prompt, image, task="general", enable_thinking=True, do_sample=True)
print(f"Prediction:\n{pred}")"""
Prediction: (as an example)
{'thinking': 'Upon examining the visual input, I observe two cats resting comfortably on a pink blanket that covers a couch or sofa. The cats are lying side by side, with one on top of the other, indicating their relaxed state and possibly their close bond. Their positions suggest they feel safe and at ease in their environment.\n\nWith my advanced visual processing capabilities, I can identify various objects within this scene, such as the pink blanket beneath the cats and the couch they are lying on. Additionally, there appear to be remote controls nearby, potentially situated on or near the couch, which further confirms that this is an indoor setting where people relax and spend leisure time.', 'answer': 'The image shows two cats lying on a pink blanket on a couch.'
}
"""
Loading Checkpoint ...
##### INPUT #####
What is shown in this image?
###############
Thinking enabled.
Running inference ...
Prediction:
{'thinking': 'Within the visual input, I see two cats lying on a couch covered with a pink blanket or sheet. The cats appear to be small and resting comfortably side by side. Additionally, there are two remotes positioned near the cats, likely belonging to devices that are commonly used while sitting on the couch.', 'answer': 'The image shows two cats lying on a couch next to each other, with a pink sheet or blanket covering them. There are also two remotes placed nearby.'}
- 视觉定位(VG)的用途
from inference import SimpleInferencemodel = SimpleInference("BAAI/RoboBrain2.0-7B")prompt = "the person wearing a red hat"
image = "./assets/demo/grounding.jpg"pred = model.inference(prompt, image, task="grounding", plot=True, enable_thinking=True, do_sample=True)
print(f"Prediction:\n{pred}")"""
Prediction: (as an example)
{'thinking': "From the visual input, I can identify two individuals: a man and a young boy. The man appears to be seated outside against a stone wall, wearing a blue top and jeans. His hands are around the young boy's waist. The boy is wearing a red baseball cap and a striped sweater, and he seems to be laughing or having fun while interacting with the man.\n\nNow focusing on the task at hand, which involves identifying the person wearing a red hat. In this scenario, it would be reasonable to deduce that the boy, who is wearing a red baseball cap, is the one wearing the red hat. The red cap stands out against the other elements in the scene due to its bright color, making it easy to pinpoint as the object in question.\n\nTherefore, based on direct visual analysis, the person wearing the red hat is indeed the young boy, and his position relative to the man is such that he is seated close to him along the stone wall.", 'answer': '[0, 193, 226, 640]'
}
"""

Loading Checkpoint ...
Grounding task detected. We automatically add a grounding prompt for inference.
##### INPUT #####
Please provide the bounding box coordinate of the region this sentence describes: the person wearing a red hat.
###############
Thinking enabled.
Running inference ...
Plotting enabled. Drawing results on the image ...
Extracted bounding boxes: [[0, 196, 234, 639]]
Annotated image saved to: result/grounding_with_grounding_annotated.jpg
Prediction:
{'thinking': "From the visual input, there is a small child sitting on a bench who appears to be enjoying a light-hearted moment with another individual. The child is noticeably wearing a bright red cap and is seated next to an adult. The child's mouth is wide open in what appears to be laughter or an expression of delight.\n\nThe task requires identifying the bounding boxes corresponding to different individuals within the scene. The child wearing the red cap, sitting on the bench, is a primary focus. This area is to the left side, highlighted by the vivid red of the hat that stands out against the surrounding colors. It provides clear boundaries for the identification of the child as the second individual in the image pair.\n\nGiven these observations, my visual processing identifies the child at the center-left section of the frame, encapsulating the key aspects like the red cap and blue clothing, as essential features for boundary definition. Thus, the coordinates [0, 196, 234, 639] effectively encompass the red-capped child within the scene.", 'answer': '[0, 196, 234, 639]'}
- 用于可负担性预测(具身化)
from inference import SimpleInferencemodel = SimpleInference("BAAI/RoboBrain2.0-7B")# Example:
prompt = "hold the cup"image = "./assets/demo/affordance.jpg"pred = model.inference(prompt, image, task="affordance", plot=True, enable_thinking=True, do_sample=True)
print(f"Prediction:\n{pred}")"""
Prediction: (as an example)
{'thinking': "From the visual input, the object is recognized as a white ceramic cup with a handle on its side. It appears cylindrical with an open top and has sufficient height for a standard drinking cup. The handle is positioned to one side, which is crucial for grasping. The cup rests on a wooden surface, suggesting stability due to its weight and material solidity.\n\nMy end-effector is equipped with a gripper capable of securely engaging objects of this size and shape, specifically designed for cylindrical and handle-like surfaces. Given my capabilities, I can adjust the grip to accommodate the handle's size and curve. The gripper can easily access the handle area without disturbing the cup's balance on the flat surface.\n\nThe current task is to hold the cup, which necessitates securely gripping it by the handle or potentially enveloping the body if necessary. The cup’s position on the table, within reach, allows me to approach from the left side toward the handle, ensuring optimal leverage for lifting. \n\nVerifying the handle's suitability, it seems sufficiently robust and unobstructed to enable a reliable grip. My sensors will ensure that the force applied through the gripper doesn't exceed the cup's weight and stability limits.\n\nTherefore, the cup's affordance area is [577, 224, 638, 310]. This is because the handle provides a clear and accessible spot for my gripper to engage securely, fulfilling the task requirement to hold the cup effectively.", 'answer': '[577, 224, 638, 310]'
}
"""
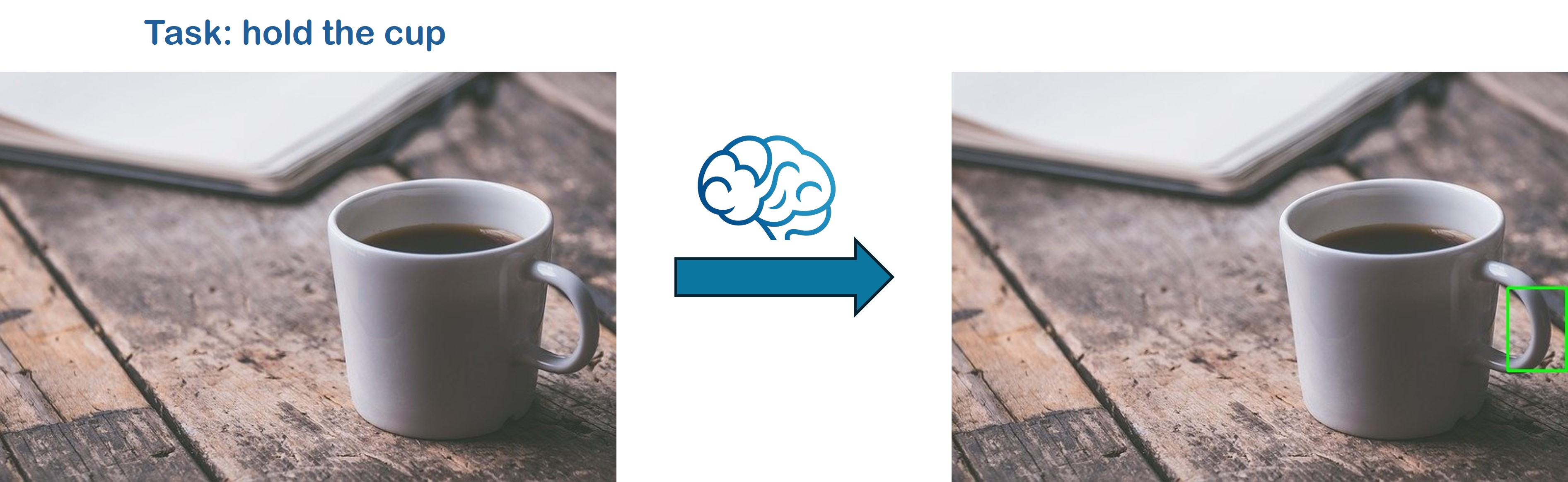
Loading Checkpoint ...
Affordance task detected. We automatically add an affordance prompt for inference.
##### INPUT #####
You are a robot using the joint control. The task is "hold the cup". Please predict a possible affordance area of the end effector.
###############
Thinking enabled.
Running inference ...
Plotting enabled. Drawing results on the image ...
Extracted bounding boxes: [[572, 216, 624, 301]]
Annotated image saved to: result/affordance_with_affordance_annotated.jpg
Prediction:
{'thinking': "From the visual input, the object is recognized as a white ceramic mug filled with a dark liquid, likely coffee. Its handle on the right side is visible and appears to be made of a similar material, suggesting durability and a proper grip for handling. The mug is positioned on a flat wooden surface, with enough clearance around it for manipulation. The current task requires holding the cup, which involves grasping its handle securely.\n\nMy end-effector, featuring a joint-controlled gripper capable of adjusting to various shapes, can effectively engage with the handle of this mug. The handle's thickness and shape seem compatible with my gripper's ability to close around objects up to a certain width. The spatial setup allows me to approach from above, ensuring any movement doesn't disturb the contents inside the mug or the surrounding environment.\n\nThe context of holding the cup indicates that I need to lift it safely without spilling its contents. The mug’s position on the table provides an optimal area for approaching from above while maintaining stability during the lifting process. \n\nTherefore, the mug's affordance area is [572, 216, 624, 301]. This location includes the handle, which suits my gripper for secure engagement. The handle's orientation and material make it suitable for grasping without instability, aligning with the task requirements.", 'answer': '[572, 216, 624, 301]'}
- 轨迹预测(实体化)的用途
from inference import SimpleInferencemodel = SimpleInference("BAAI/RoboBrain2.0-7B")# Example:
prompt = "reach for the banana on the plate"image = "./assets/demo/trajectory.jpg"pred = model.inference(prompt, image, task="trajectory", plot=True, enable_thinking=True, do_sample=True)
print(f"Prediction:\n{pred}")"""
Prediction: (as an example)
{'thinking': 'From the visual input, the target object, a banana, is placed upon a circular plate towards the center-right of the table. My end-effector is positioned near the left edge of the table, ready to initiate movement. A spatial analysis of the scene reveals potential obstructions such as various dishes and objects around the plate. The plate itself defines the immediate vicinity of the target.\n\nMy joint control system enables me to generate smooth trajectories for my end-effector. I will plan a sequence starting from my current position, moving across the table until it reaches the banana, while ensuring clearance from obstacles. The trajectory must be efficient in reaching the target without unnecessary detours or collisions.\n\nThe task is to "reach for the banana on the plate", necessitating a path that begins at my current location and terminates at or very near the banana. Up to 10 key points can be utilized, but fewer may suffice if the path is straightforward.\n\nI verify the proposed path by mentally simulating the trajectory. Considering the table layout, the path needs to navigate away from the nearest glass and avoid the bottle on the right-hand side. Each segment of the trajectory should present sufficient clearance from these objects. The final point must precisely align with the banana\'s location on the plate.\n\nTherefore, based on direct vision analysis, motion planning capabilities, and task requirements, the trajectory points to reach the banana are determined as follows: [(137, 116), (169, 94), (208, 84), (228, 80)]. This sequence forms a viable path from the current end-effector position to the target, respecting the visual environment.', 'answer': '[(137, 116), (169, 94), (208, 84), (228, 80)]'
}
"""

Loading Checkpoint ...
Trajectory task detected. We automatically add a trajectory prompt for inference.
##### INPUT #####
You are a robot using the joint control. The task is "reach for the banana on the plate". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. [[x1, y1], [x2, y2], ...], where each tuple contains the x and y coordinates of a point.
###############
Thinking enabled.
Running inference ...
Plotting enabled. Drawing results on the image ...
Extracted trajectory points: [[(148, 130), (167, 91), (212, 83)]]
Annotated image saved to: result/trajectory_with_trajectory_annotated.jpg
Prediction:
{'thinking': 'From the visual input, the target object, a banana, is clearly identified resting upon a round plate positioned towards the back of the scene on the table. The current position of my end-effector is located to the left side of the table. The path to the banana involves navigating around several other items such as a coffee mug and a ketchup bottle which are nearby but not directly obstructing the direct line to the banana. The path appears relatively clear apart from these items.\n\nMy joint control system allows me to generate a smooth and precise path for my end-effector. I will plan a sequence of movements that begins at my current position and culminates at or very near the banana on the plate. The trajectory will avoid unnecessary collisions while ensuring efficient movement.\n\nThe task requires reaching for the banana on the plate. This implies initiating motion from the current position and terminating close enough to interact effectively with the banana. Up to 10 key points allow for a detailed path if needed, but given the simplicity of avoiding only two other objects, fewer points may suffice.\n\nA verification of the planned path ensures the sequence forms a logical progression toward the banana. Each segment is mentally simulated to confirm clearance from the coffee mug and ketchup bottle, maintaining a direct course. The final point targets the banana accurately.\n\nTherefore, based on visual analysis and motion planning, the key trajectory points to reach for the banana on the plate are determined to be [(148, 130), (167, 91), (212, 83)]. This sequence provides an efficient and collision-free path from the current position to the target.', 'answer': '[(148, 130), (167, 91), (212, 83)]'}
- 指向预测的用法(具身化)
from inference import SimpleInferencemodel = SimpleInference("BAAI/RoboBrain2.0-7B")# Example:
prompt = "Identify several spots within the vacant space that's between the two mugs"image = "./assets/demo/pointing.jpg"pred = model.inference(prompt, image, task="pointing", plot=True, enable_thinking=True, do_sample=True)
print(f"Prediction:\n{pred}")"""
Prediction: (as an example)
{'thinking': 'From the visual input, there is a clear division between two mugs with distinct colors: one blue and one green. The blue mug is positioned towards the left side, while the green mug is on the right side of the scene. The task requires identifying spots between these two mugs.\n\nMy visual processing allows me to focus on the area between the blue mug and the green mug. This region appears to be moderately uniform in texture relative to the surrounding surfaces. I see no significant objects or textures interfering directly between them, suggesting an open space suitable for placing points.\n\nTo fulfill the requirement of identifying multiple spots within this vacant region, I will select distinct pixel coordinates that lie between the mugs, ensuring they are not centered on the mugs themselves or any visible obstructions. My approach involves choosing several points distributed across this gap, maintaining a reasonable spread to reflect "several" distinct locations.\n\nVerification ensures each selected point lies strictly within the visible vacant space between the two cups, away from the edges or any mugs\' contours. Distinctness among points is confirmed to ensure no overlap occurs.\n\nThus, based on direct visual analysis and task requirements, identified points within the vacant area between the two mugs include (376, 309), (332, 357), (384, 335), (343, 296), (348, 327), (328, 346), (371, 322), (392, 303), (380, 324), and (337, 295). These points satisfy all conditions specified by the task.','answer': '[(376, 309), (332, 357), (384, 335), (343, 296), (348, 327), (328, 346), (371, 322), (392, 303), (380, 324), (337, 295)]'
}
"""

7. 导航任务(实体化)的使用
from inference import SimpleInferencemodel = SimpleInference("BAAI/RoboBrain2.0-7B")# Example 1:
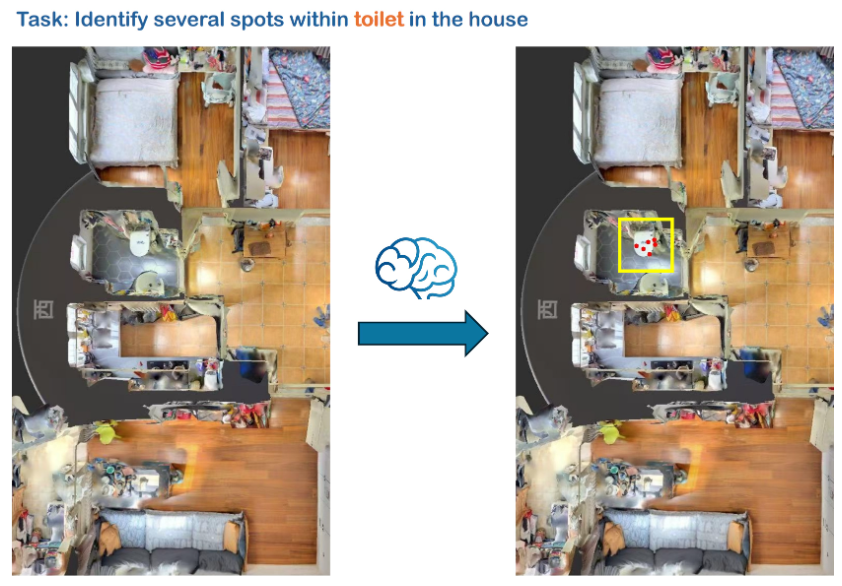
prompt_1 = "Identify several spots within toilet in the house"image = "./assets/demo/navigation.jpg"pred = model.inference(prompt_1, image, task="pointing", plot=True, enable_thinking=True, do_sample=True)
print(f"Prediction:\n{pred}")# Example 2:
prompt_2 = "Identify several spots within the sofa that can be used for sitting"image = "./assets/demo/navigation.jpg"pred = model.inference(prompt_2, image, task="pointing", plot=True, enable_thinking=True, do_sample=True)
print(f"Prediction:\n{pred}")"""
Prediction: (as an example 1: toilet)
{'thinking': 'From the visual input, I discern the presence of a toilet located centrally on the tiled floor within the frame. Its rectangular form is evident against the darker-toned tiles adjacent to lighter-colored ones, providing visual contrast. I focus on identifying points that accurately represent distinct locations on the toilet\'s surface to satisfy the task requirement.\n\nMy advanced visual processing allows me to segment this toilet from its surrounding elements effectively. Points must be selected such that they do not overlap with other objects or textures interfering with recognizing the toilet specifically. The smooth surface and consistent texture of the toilet allow for precise point identification across its visible areas.\n\nThe task explicitly requires identifying several spots within the toilet. I proceed by carefully selecting multiple distinct coordinates distributed across the toilet’s surface, ensuring they reflect varied positions. These spots are verified to lie strictly within the boundaries of the toilet itself while maintaining their distinctness and avoiding redundancy.\n\nFollowing my visual analysis, I determine the points (318, 445), (293, 466), (307, 478), (277, 459), (320, 456), and (304, 450) as valid choices. These coordinates are well-distributed over the toilet’s surface, ensuring adherence to the task requirements to locate "several" spots.', 'answer': '[(318, 445), (293, 466), (307, 478), (277, 459), (320, 456), (304, 450)]'
}Prediction: (as an example 2: sofa)
{'thinking': "From the visual input, my attention is drawn to a sofa situated against a wooden wall with a distinct texture apparent through its surface pattern. The sofa is composed of cushions and has an apparent soft, inviting structure suitable for sitting. The task requires identifying specific spots on this sofa that can be used comfortably.\n\nThe sofa lies horizontally across the bottom section of the image, extending along the floor's edge. The cushions appear to be evenly spaced, providing consistent seating options. The primary focus area involves pinpointing these regions for potential sitting spots—ensuring they lie within the visible seating area without touching the edges or overlapping any other objects or features.\n\nAs I systematically examine this region, I focus on the cushioned parts of the sofa where there are no structural interruptions or obstructions. These smooth areas provide optimal surfaces for sitting. By assessing the sofa visually, I can select points that are spaced adequately apart, ensuring comfort and utility.\n\nUpon verification, I confirm that these chosen coordinates represent well-distributed points over the entire seating area of the sofa, avoiding any overlaps or intrusions into non-cushioned sections. Each point thus falls distinctly within the intended zone for sitting.\n\nConsequently, based on this direct visual analysis, I identify the following points: (369, 1197), (385, 1190), (359, 1176), and (387, 1172). These coordinates are within the defined couch area, ensuring they comply with the task requirements effectively.", 'answer': '[(369, 1197), (385, 1190), (359, 1176), (387, 1172)]'
}
"""