有什网站可以做设计赚钱百度图片搜索网页版
文章目录
- 需求
- 所需第三方库
- requests
- 实战教程
- 打开网站
- 抓包
- 添加请求头等信息
- 发送请求,解析数据
- 修改翻译内容以及实现中英互译
- 完整代码
需求
目标网站:
https://fanyi.so.com/#
要求:爬取360翻译数据包,实现翻译功能
所需第三方库
requests
简介
requests 模块是 python 基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。
安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy
实战教程
打开网站
https://fanyi.so.com/#

进入网站之后鼠标右击检查,或者F12来到控制台,点击网络,然后刷新。
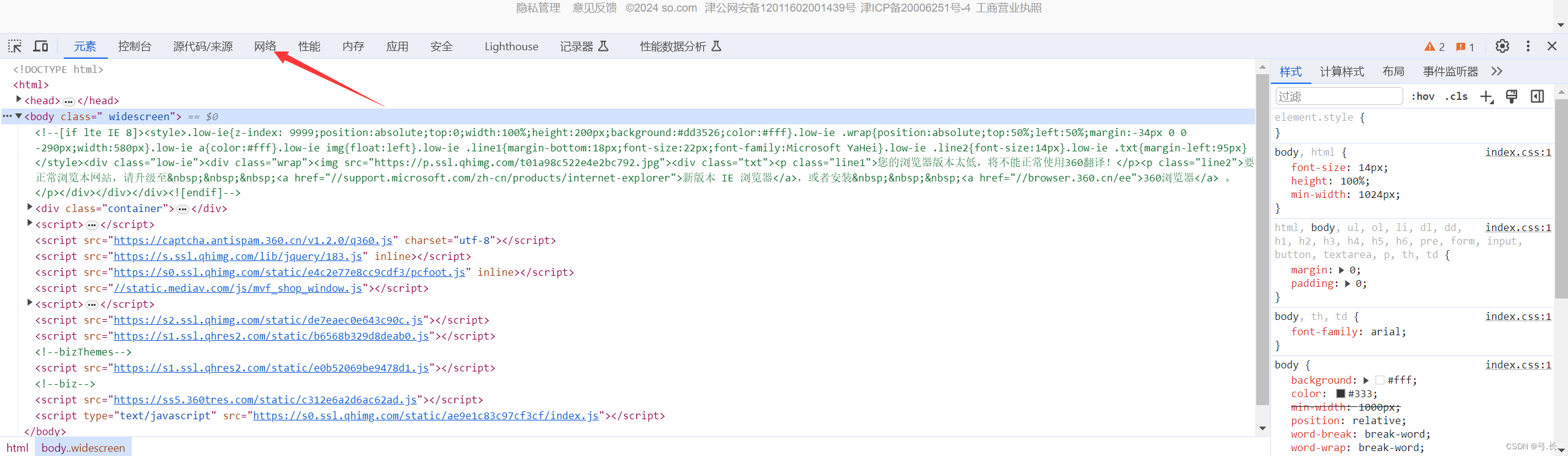
抓包
点击网络刷新之后,在点击Fetch/XHR,随意输入一个单词,点击翻译会发现出现一个数据包,这个数据包就是我们所需要的。

点击这个数据包,然后点击标头,这里就有我们所需要的请求网址
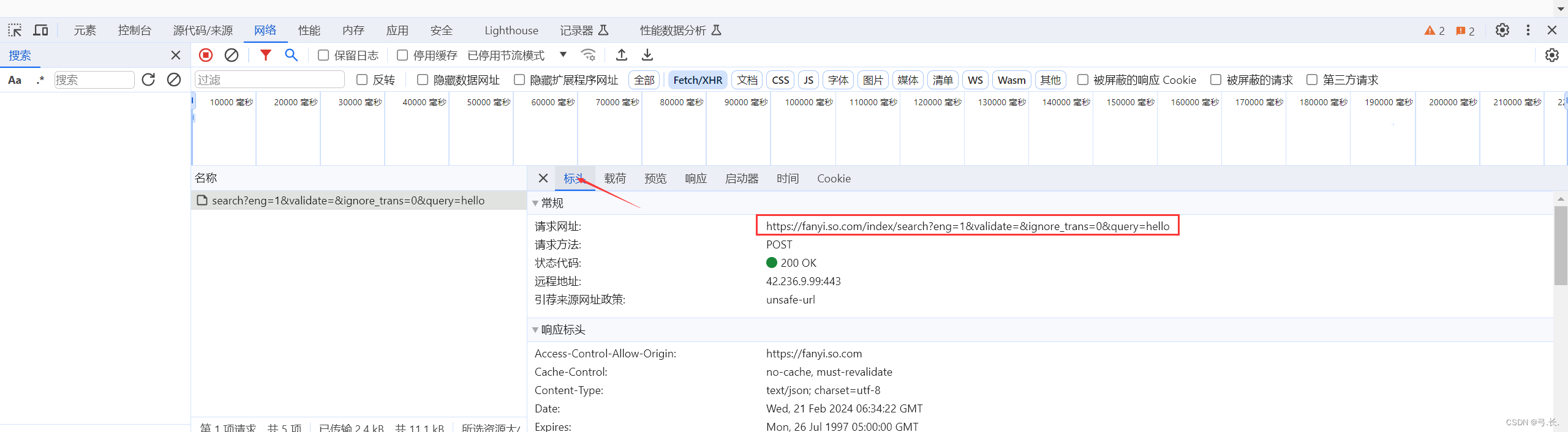
# 导入requests模块
import requests# 请求网址
url = 'https://fanyi.so.com/index/search?eng=1&validate=&ignore_trans=0&query=hello'
添加请求头等信息
一般网站都会设置一定的反爬机制。很多爬虫向服务器请求数据,或者爬虫要请求很多信息时,会给服务器造成很大压力,严重时可能导致服务器宕机,那么,针对爬虫就会产生对应的反爬机制,比如识别user-agent就是一个初级的反爬机制,当访问者没有携带user-agent时,网站就会默认访问者是爬虫,从而可以拒绝提供信息反馈。
在标头下面有请求标头,把这些全部复制下来就行。

# 获取请求头信息
headers = {'Accept': 'application/json, text/plain, */*','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','Content-Length': '0','Cookie': 'QiHooGUID=F02A63E0BCB72DB4A01C21FA023475E1.1703769301607; Q_UDID=00b0237e-501b-1360-b2eb-96b79d1ac5ec; __guid=144965027.253643186935022000.1703769305042.223; count=2','Origin': 'https://fanyi.so.com','Pro': 'fanyi','Referer': 'https://fanyi.so.com/','Sec-Ch-Ua': '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"','Sec-Ch-Ua-Mobile': '?0','Sec-Ch-Ua-Platform': '"Windows"','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'same-origin','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
发送请求,解析数据
在获取请求网址那里可以看到,这个数据包是POST请求。也就是说我们需要额外的参数。点击载荷,下面这些就是我们所需要的数据。

# post请求所需要的额外参数(数据类型为字典数据类型)
data_dic = {'eng': 1,'ignore_trans': 0,'query': 'hello'
}
# 发送请求,获取响应
res = requests.post(url, headers=headers, data=data_dic)
解析数据,打印翻译内容
点击预览可以看到,fanyi就是我们之前输入的单词翻译后的内容。现在只需要通过字典的形式取取值就可以得到翻译后的内容。
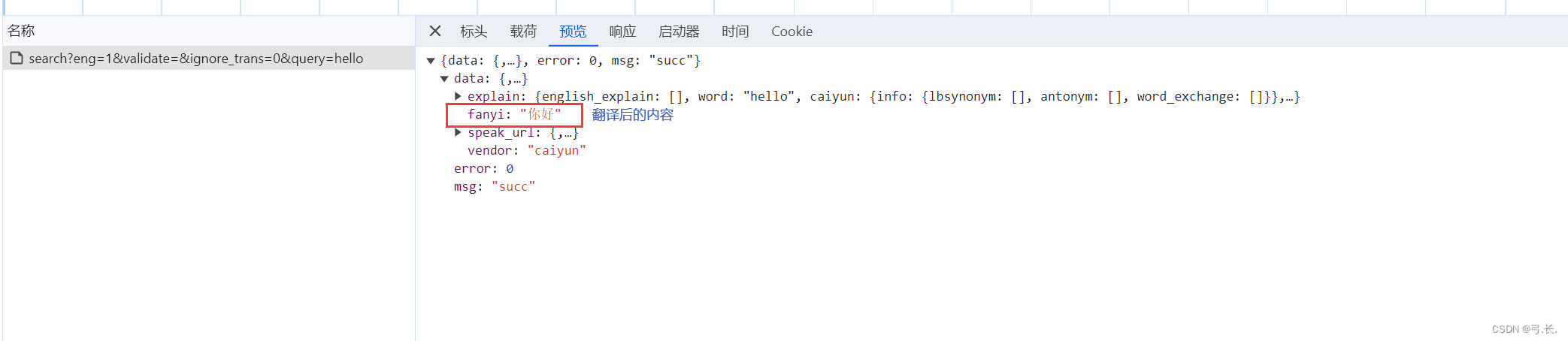
data_dic = {'eng': 1,'ignore_trans': 0,'query': 'hello'
}
# 发送请求,获取响应
res = requests.post(url, headers=headers, data=data_dic)
# 将响应内容转化成json数据类型
data = res.json()
# 打印翻译内容
print(data['data']['fanyi'])

修改翻译内容以及实现中英互译
从之前载荷里的数据可以猜出query就是我们所输入的单词,那么我们直接用input去代替我们所要翻译的单词就可以了。
# 改变query的值
word = input('请输入你要翻译的内容:')
# post请求所需要的额外参数(数据类型为字典数据类型)
data_dic = {'eng': 1,'ignore_trans': 0,'query': word
}
# 发送请求,获取响应
res = requests.post(url, headers=headers, data=data_dic)
# 将响应内容转化成json数据类型
data = res.json()
# 打印翻译内容
print(data['data']['fanyi'])

实现中英互译
可以看到,目前程序只能实现英译中,是无法实现中译英的。

现在我们不妨先试验一下,用360翻译实现中译英,现在我们发现,载荷数据第一行eng在英译中时的值是1,现在中译英之后就变成了0,也就说明,是英译中还是中译英就取决于这个参数。所以现在我们只要判断在程序中输入的是中文还是英文就行啦。

我们知道,python中UTF-8编码下,一个英文字符占1个字节,一个中文字符(通常是汉字)占3个字节。,所以我们只要判断程序中输入的第一个字的字节长度,就可以判断输入的是中文还是英文啦。
# 改变query的值
word = input('请输入你要翻译的内容:')
# 获取输入的内容是中文还是英文
lenght = len(word[0].encode('utf-8'))
# 判断,如果输入的是中文,这翻译为英文;如果输入的是英文,这翻译为中文
if lenght == 3:eng = 0
else:eng = 1
# post请求所需要的额外参数(数据类型为字典数据类型)
data_dic = {'eng': eng,'ignore_trans': 0,'query': word
}
# 发送请求,获取响应
res = requests.post(url, headers=headers, data=data_dic)
# 将响应内容转化成json数据类型
data = res.json()
# 打印翻译内容
print(data['data']['fanyi'])

这样我们就实现中英互译啦。当然还可以在原先的基础上在改进一下,比如可以加一个死循环,实现多次翻译等等。
完整代码
# 导入requests模块
import requests# 获取360翻译的翻译的数据包地址
url = 'https://fanyi.so.com/index/search?eng=1&validate=&ignore_trans=0&query=hello'
# 获取请求头等伪装信息
head = {'Accept': 'application/json, text/plain, */*','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','Content-Length': '0','Cookie': 'QiHooGUID=F02A63E0BCB72DB4A01C21FA023475E1.1703769301607; Q_UDID=00b0237e-501b-1360-b2eb-96b79d1ac5ec; __guid=144965027.253643186935022000.1703769305042.223; count=2','Origin': 'https://fanyi.so.com','Pro': 'fanyi','Referer': 'https://fanyi.so.com/','Sec-Ch-Ua': '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"','Sec-Ch-Ua-Mobile': '?0','Sec-Ch-Ua-Platform': '"Windows"','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'same-origin','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 运行之后可以反复翻译
while 1:# 改变query的值word = input('请输入你要翻译的内容:')# 获取输入的内容是中文还是英文lenght = len(word[0].encode('utf-8'))# 判断,如果输入的是中文,这翻译为英文;如果输入的是英文,这翻译为中文if lenght == 3:eng = 0else:eng = 1# post请求所需要的额外参数(数据类型为字典数据类型)data_dic = {'eng': eng,'ignore_trans': 0,'query': word}# 发送请求,获取响应res = requests.post(url, headers=head, data=data_dic)# 将响应内容转化成json数据类型data = res.json()# 打印翻译内容print(data['data']['fanyi'])